B+树查询详解
数据页
数据库的 I/O 操作的最小单位是页,InnoDB 数据页的默认大小是 16KB,意味着数据库每次读写都是以 16KB 为单位的,一次最少从磁盘中读取 16K 的内容到内存中,一次最少把内存中的 16K 内容刷新到磁盘中。
数据页的结构:
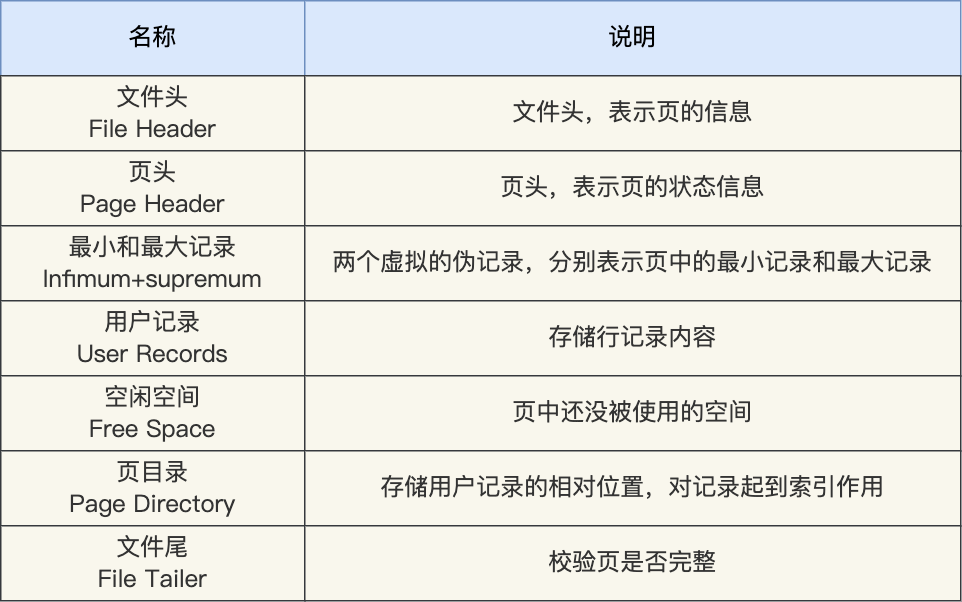
在 File Header 中有两个指针,分别指向上一个数据页和下一个数据页,连接起来的页相当于一个双向的链表,如下图所示:
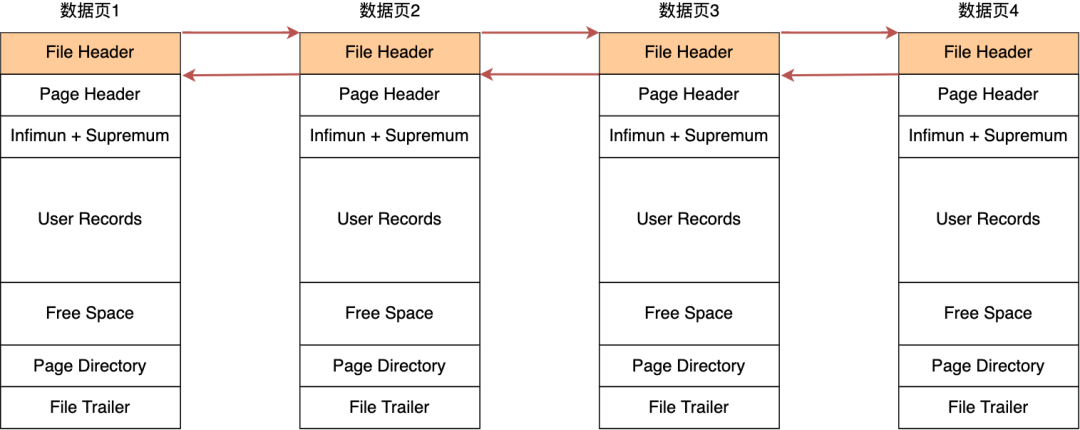
这也就是聚簇索引B+树的叶子节点,采用链表的结构是让数据页之间形成逻辑上的连续,
数据页的主要作用是存储记录,也就是数据库的数据,数据页中的记录按照「主键」顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。
因此,数据页内部有一个页目录,起到记录的索引作用,数据页中的页目录就是为了能快速找到记录。
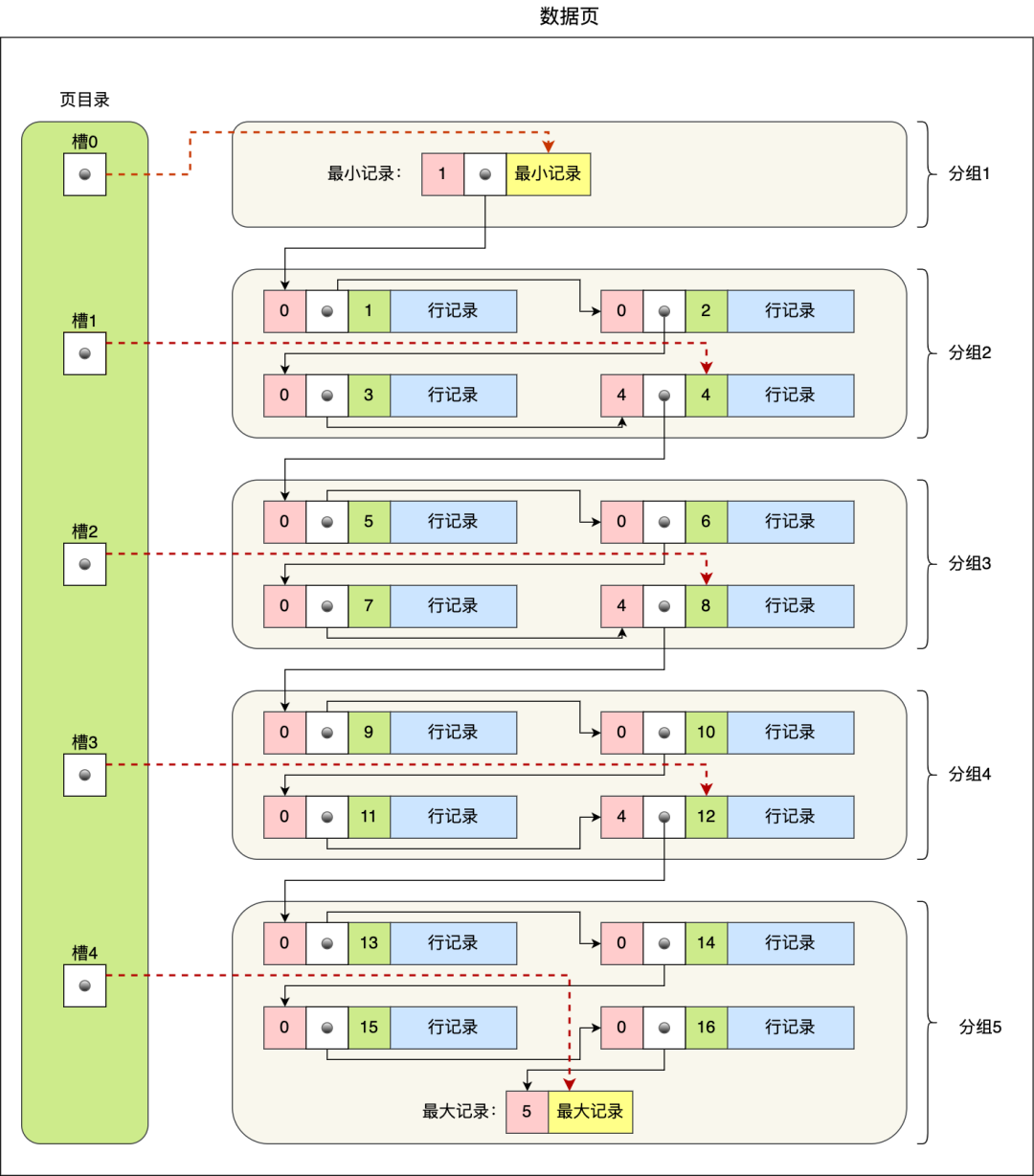
页目录的创建过程
- 将所有的记录划分成几个组,这些记录包括最小记录和最大记录,但不包括标记为“已删除”的记录;
- 每个记录组的最后一条记录就是组内最大的那条记录,并且最后一条记录的头信息中会存储该组一共有多少条记录,作为 n_owned 字段(上图中粉红色字段)
- 页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起来,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一个记录。
页目录就是由多个槽组成的,槽相当于分组记录的索引。记录是按照「主键值」从小到大排序的,所以我们通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到对应的记录,无需从最小记录开始遍历整个页中的记录链表。
5 个槽的编号分别为 0,1,2,3,4,我想查找主键为 11 的用户记录:
- 先二分得出槽中间位是 (0+4)/2=2 ,2号槽里最大的记录为 8。因为 11 > 8,所以需要从 2 号槽后继续搜索记录;
- 再使用二分搜索出 2 号和 4 槽的中间位是 (2+4)/2= 3,3 号槽里最大的记录为 12。因为 11 < 12,所以主键为 11 的记录在 3 号槽里;
- 再从 3 号槽指向的主键值为 9 记录开始向下搜索 2 次,定位到主键为 11 的记录,取出该条记录的信息即为我们想要查找的内容。
B+树
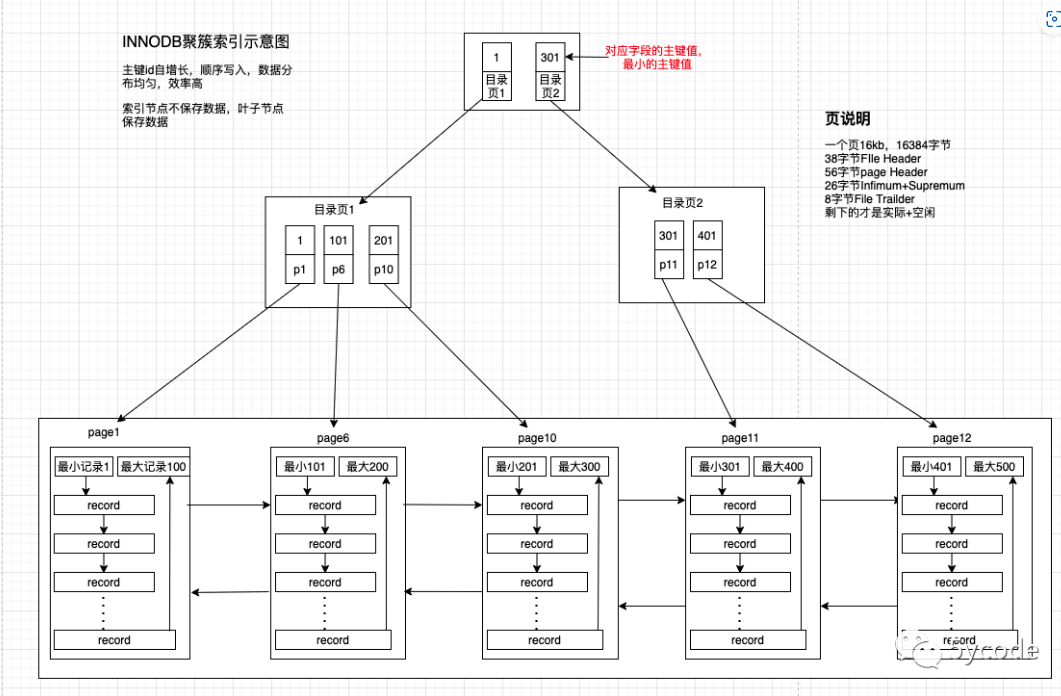
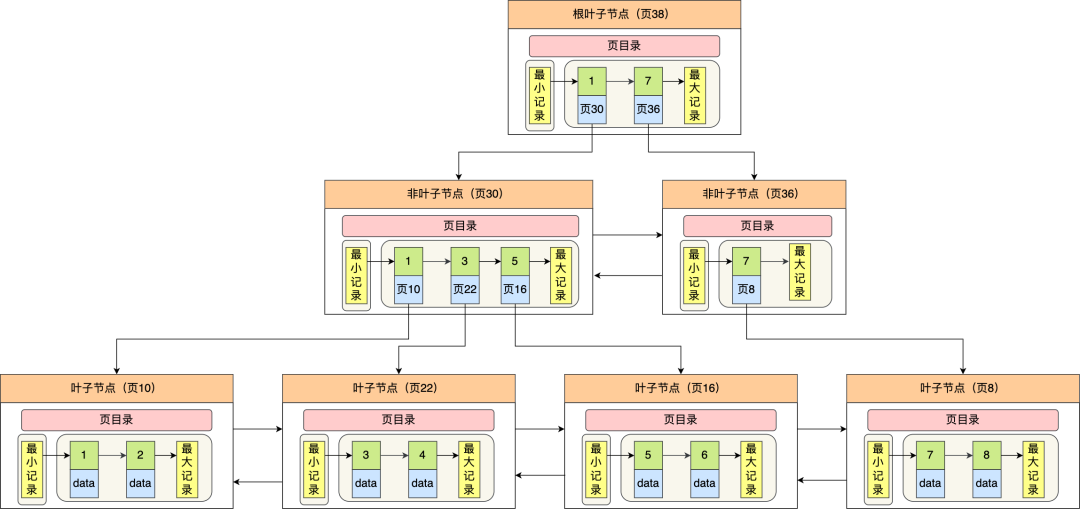
我们再看看 B+ 树如何实现快速查找主键为 6 的记录,以上图为例子:
- 从根节点开始,通过二分法快速定位到符合页内范围包含查询值的页,因为查询的主键值为 6,在[1, 7)范围之间,所以到页 30 中查找更详细的目录项;
- 在非叶子节点(页30)中,继续通过二分法快速定位到符合页内范围包含查询值的页,主键值大于 5,所以就到叶子节点(页16)查找记录;
- 接着,在叶子节点(页16)中,通过槽查找记录时,使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到主键为 6 的记录。
可以看到,在定位记录所在哪一个页时,也是通过二分法快速定位到包含该记录的页。定位到该页后,又会在该页内进行二分法快速定位记录所在的分组(槽号),最后在分组内进行遍历查找。
总结
B+树的查询依靠页内目录,InnoDB会为每个数据页建立页内目录,数据页的记录会被分为若干个组,一个组对应目录的一个槽,槽内存储的实际上是偏移地址
每一个槽会指向这些组中的最大记录,因为第一个分组只能有一个,所以页目录的第一个槽指向整个页最小的记录,最后一个槽指向最大的记录
当我们要进行查询时,使用二分法分别在各个数据页中进行查询,直到到达叶节点。如果是范围查询,因为B+树页节点依靠主键排序,则可以直接依靠双向链表的前驱指针和后继指针进行范围结果输出。