Golang调度详解
Goroutine
Goroutine可以看作对thread加的一层抽象,它更轻量级,可以单独执行。
因为有了这层抽象,我们不会直接面对thread,我们只会看到代码里的goroutine。
操作系统却相反,管你什么 goroutine,我才没空理会。我安心地执行线程就可以了,线程才是我调度的基本单位。
而这也是基于两级线程模型实现的,Goroutine与内核线程是多对多的关系,也叫M:N模型
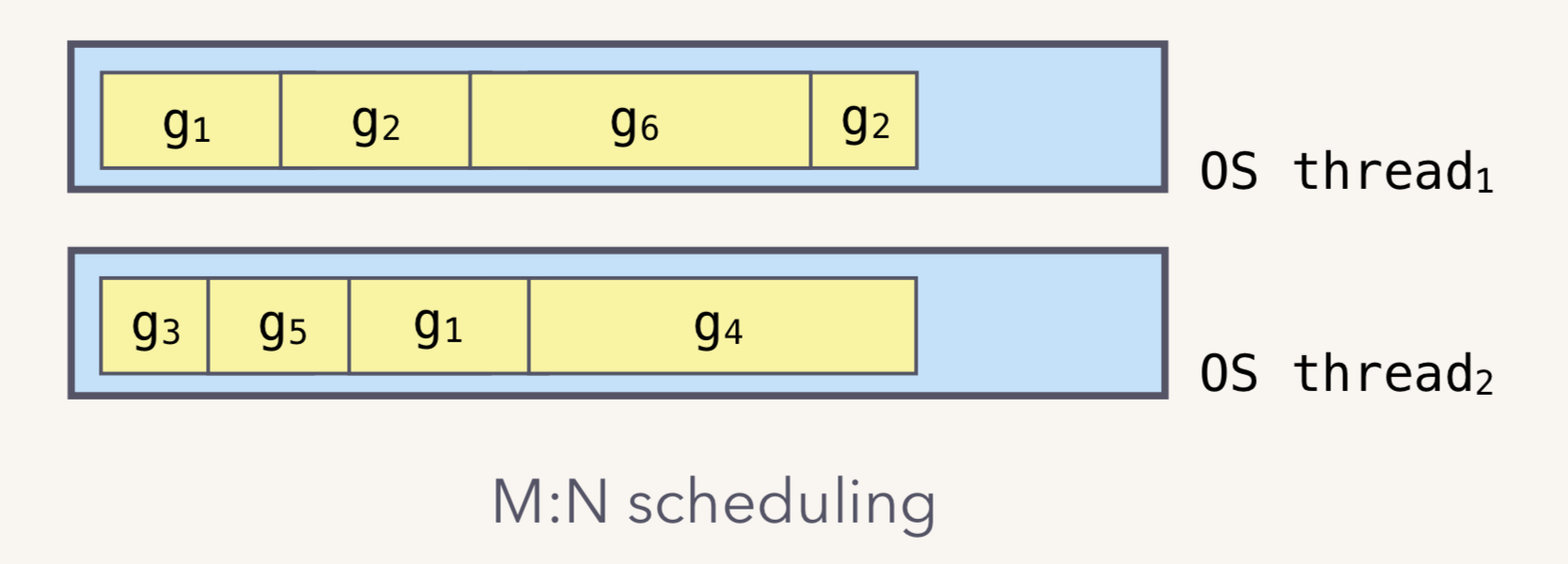
Go runtime 会负责 goroutine的生老病死,从创建到销毁。Runtime 会在程序启动的时候,创建 M 个线程(CPU 执行调度的单位),之后创建的 N 个 goroutine 都会依附在这 M 个线程上执行。
在同一时刻,一个线程上只能跑一个 goroutine。当 goroutine 发生阻塞时,runtime 会把当前 goroutine 调度走,让其他 goroutine 来执行。目的就是不让一个线程闲着,榨干 CPU 的每一滴油水。所以一个线程内的Goroutine一定是串行的。
Goroutine和thread有什么区别?
- 内存占用:创建一个 goroutine 的栈内存消耗为2 KB,实际运行过程中,如果栈空间不够用,会自动进行扩容。创建一个 thread 则需要消耗 1 MB 栈内存,对于一个用 Go 构建的 Web Server而言,对到来的每个请求,直接创建一个goroutine用来处理是非常轻松的一件事(可以读源码)。而如果使用线程如JAVA实现的BIO模式,每个请求对应一个线程则太浪费资源了,很快就会出 OOM 错误
- 创建和销毀:Thread创建和销毀都会有巨大的消耗,因为是内核态的,通常解决的办法就是线程池实现复用,避免频繁的创建和销毁。而 goroutine因为是由Go runtime负责管理的,全程在用户态进行,创建和销毁的消耗非常小。
- 切换:当 threads 切换时,需要保存各种寄存器,以便将来恢复,而goroutines 切换只需保存三个寄存器,切换成本非常小
在golang中,Goroutine被分为三种
- g:执行普通代码的G
- g0:执行调度器代码的G,栈内存大小固定为8M,不可以动态伸缩
- main goroutine:执行初始化工作的G
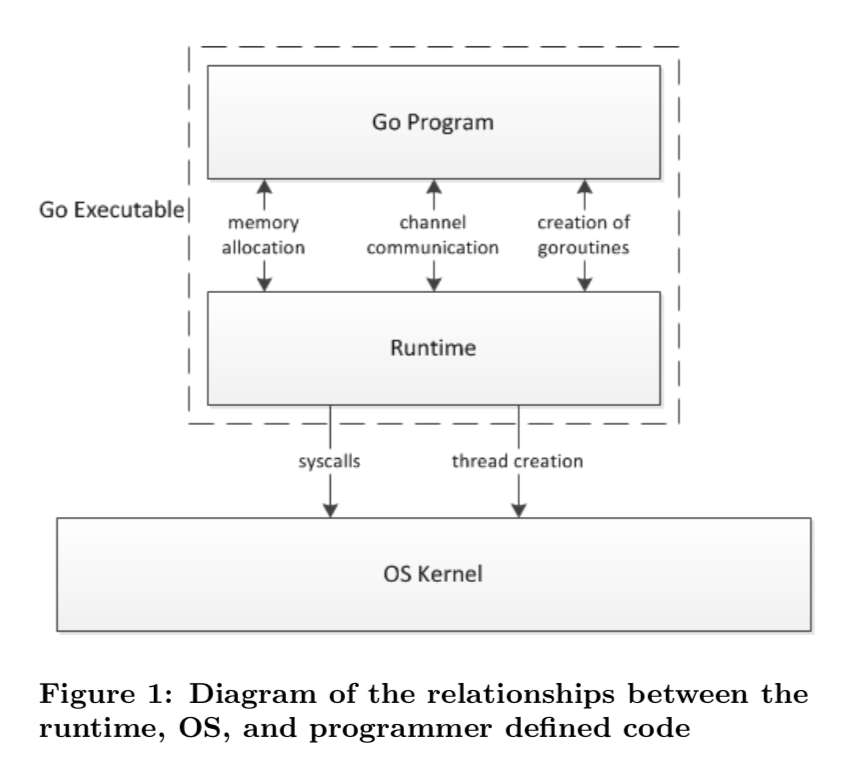
Go 程序的执行由两层组成:Go Program,Runtime。它们之间通过函数调用来实现内存管理、channel 通信、goroutines 创建等功能。用户程序进行的系统调用都会被 Runtime 拦截,以此来帮助它进行调度以及垃圾回收相关的工作
可以说runtime相当于一个中介,将Goroutine抽象到内核态以及将内核线程抽象到用户态,并承接各类调度,通信,GC,让用户和内核各司其职,用户只能看见Goroutine,内核只能看见线程。这就是两级线程模型实现的核心所在
用三个基础的结构体来实现goroutines的调度:
- G:代表一个 goroutine,包含:表示 goroutine 栈的一些字段,指示当前 goroutine 的状态,指示当前运行到的指令地址,也就是PC
- M:内核线程在用户态的抽象,包含正在运行的goroutine等字段。
- P:代表一个虚拟的Processor,Go 程序启动后,会给每个OS逻辑核心分配一个 P,它维护一个处于 Runnable状态的队列
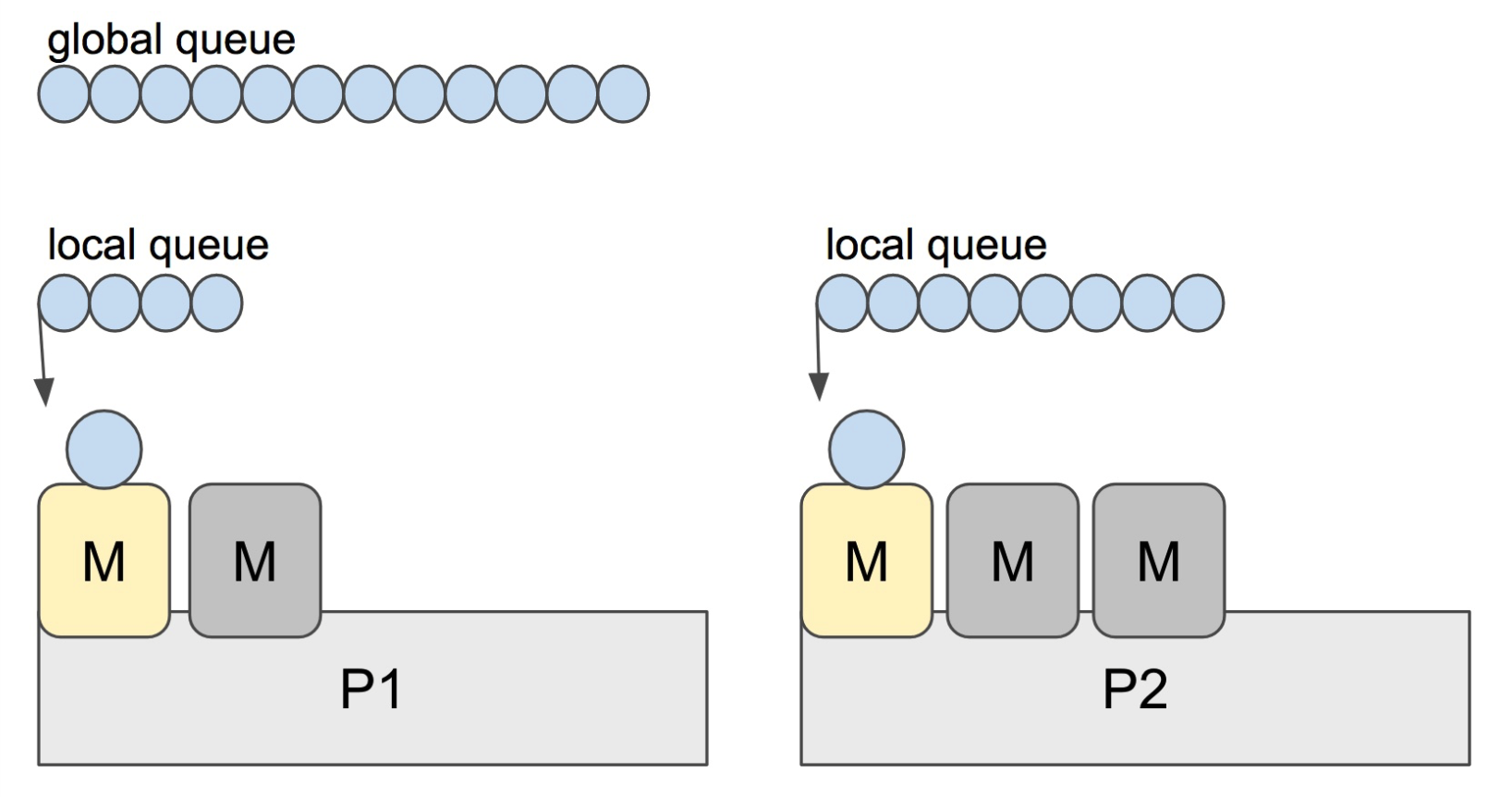
这个图应该非常直观易懂,内核线程被抽象为M,这些M跑在个数最多为 GOMAXPROCS 的逻辑处理器P上
Go 调度器中有两个不同的运行队列:全局运行队列(GRQ)和本地运行队列(LRQ)
每个M必须依附于一个 P,每个P在同一时刻只能运行一个 M,每个P都有一个LRQ,用于管理分配给在P的上下文中执行的 Goroutine,这些Goroutine轮流被和P绑定的M进行上下文切换。
GRQ存放尚未分配给P的 Goroutines,其中有一个过程是将 Goroutines从GRQ转移到LRQ
如果P上的M阻塞了,那就需要其他M来运行LRQ里的goroutine
为什么需要P
- Go的早期版本,并没有P这个结构,Go会给M直接分配一个全局队列,每个M会直接从队列中获取要运行的G,因此需要获取一个全局的锁,当并发量大的时候,锁就成了瓶颈,这反而降低了并发性能。而加入逻辑处理器,每个逻辑处理维护自己的本地队列,解决了全局锁带来的性能问题
- 逻辑处理器实现了性能的最大化,当某个M阻塞时,P可以立即将G切换到另一个M上
为什么没有Goroutine ID
我们知道,每个线程都有一个Thread Id,当进行偏向锁的加锁时,会在对象头内保存可重入的线程ID,而且线程ID也可以很容易地实现thread-local storage,只需要以线程的 ID 作为 key 的一个 map 就可以实现线程私有变量。但是Goroutine却没有这个标志位,应该说,go语言的开发者没有提供获取ID的API,为啥要这么设计呢?
- Goroutine-local storage 的GC非常麻烦,成本远远超过它的收益
- go开发者认为,goroutine就应该是无名之辈,如果为它们指定ID,他们每一个都会变得特别,而无法以同等身份来进行并发计算
- 如果将每个请求状态与goroutine id相关联,则客户端在服务请求时将无法使用更多的goroutine。比如net/http中。
- 使用图形系统库(这些库要求所有处理都发生在“主线程”上)时,在并发语言中部署会极大受限。特殊goroutine的存在迫使程序员更改程序,以避免意外操作错误的线程而导致的崩溃和其他问题。
Scheduler
Go scheduler是Go runtime的一部分,它内嵌在 Go 程序里,和 Go 程序一起运行。因此它运行在用户空间,在 kernel 的上一层。
Go scheduler 的职责就是将所有处于 runnable的 goroutine均匀分布到在P上运行的M
和Os scheduler 抢占式调度(preemptive)不一样,Go scheduler 采用协作式调度(cooperating)。
不过这个协作又和python的协作不太一样,对于传统的协作式调度,用户可以自行设定调度点,例如java和python中的yield(线程让出),但是由于在 Go 语言里,goroutine调度的事情是由Go runtime 来做,并非由用户控制,而只是存在于用户态中。
我们来看看Goroutine的上下文结构体,它用来保存 goroutine 的调度信息:
1 | |
Go scheduler会不断循环调用**runtime.schedule()**去调度 goroutines,而每个 goroutine执行完成并退出之后,会再次调用 runtime.schedule(),使得调度器回到调度循环去执行其他的 goroutine,不断循环,永不停歇。 **runtime.schedule()**每一轮调度要做的工作就是找到处于 runnable 的 goroutine,并执行它,找的顺序如下:
- 先从全局队列中寻找G
- 若全局队列中未找到,寻找P的本地队列
- 若都没有找到,就会启动work stealing
- 若work stealing失败,则阻塞
当我们使用 go 关键字启动一个新 goroutine 时,最终会调用 runtime.newproc –> runtime.newproc1,来得到 G
runtime.newproc1 会先从P的gfree缓存链表中查找可用的 g,若缓存未生效,则会新创建 g 给当前的业务函数,最后这个 g 会被传给 runtime.gogo 去真正执行
runtime.gogo由汇编语言实现,是真正去执行 goroutine 代码的函数,参数是上文提到的gobuf,它的作用的就是将M的堆栈信息切换为指定的Goroutine,这里涉及到一些PC,SP,BP寄存器指针的更新。
Scheduler面对同步系统调用
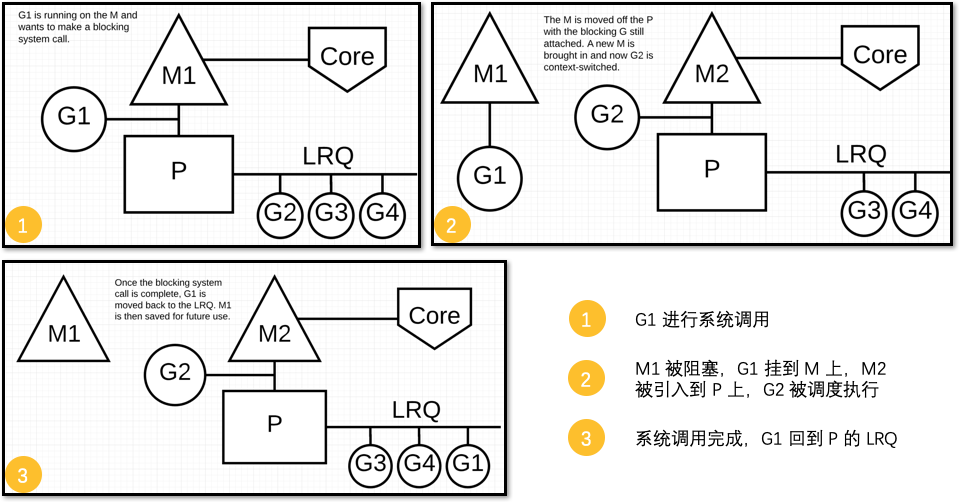
调度器介入后,识别出G1已导致M1阻塞,此时,调度器将M1与P分离,同时也将G1带走。
然后调度器引入新的M2来服务P。此时,可以从 LRQ 中选择G2并在M2上进行上下文切换。
M1则会被暂停,待到需要时再“放”出来。
Scheduler面对异步系统调用
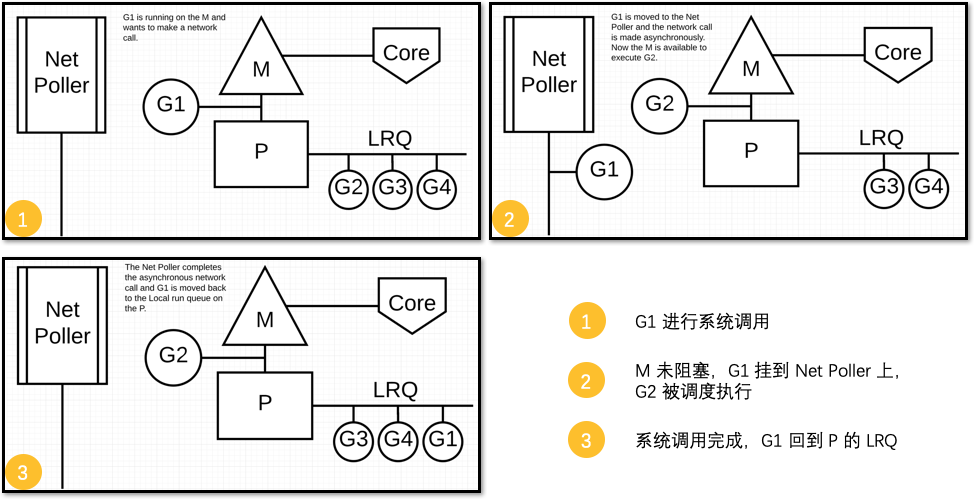
M 不会被阻塞,G 的异步请求会被“代理人” network poller 接手,G 也会被绑定到 network poller,等到系统调用结束,G 才会重新回到 P 上。M 由于没被阻塞,它因此可以继续执行 LRQ 里的其他 G
work stealing
若找到一个可执行的 goroutine后,就会一直执行下去,直到被阻塞。
当一个 P 发现自己的 LRQ 已经没有 G 时,会从其他 P 偷 一些 G 来运行,这就是work stealing。当 P2 上的一个G执行结束,它就会去 LRQ 获取下一个 G 来执行。如果 LRQ 已经空了,就是说本地可运行队列已经没有 G 需要执行,并且这时 GRQ 也没有 G 了。
这时,P2 会随机选择一个 P(称为 P1),P2 会从 P1 的 LRQ “偷”过来一半的G,保证了在高并发状况下,所有的P都不会闲着。
netpoller(epoll版本)
当你的操作系统需要异步处理系统调用时,可以使用网络轮询器。通过在这些操作系统中使用 kqueue(MacOS),epoll(Linux)或 iocp(Windows)来实现。基于网络的系统调用可以由我们今天使用的许多操作系统异步处理。
Golang为了处理网络IO也封装了异步系统调用,称为netpoller,通过对epoll的封装和优化,调度器可以防止 Goroutine在进行这些系统调用时阻塞M。而是封存 goroutine然后让出 CPU 的使用权从而令 P 可以去调度本地调度队列里的下一个 goroutine。
1 | |
1 | |
netpoller把网络 I/O 的控制权牢牢掌握在 Go 自己的 runtime 里,用户进程将始终存在于用户态,可以始终接受Go强大的 runtime scheduler来调度业务程序的并发,实现性能的最大化
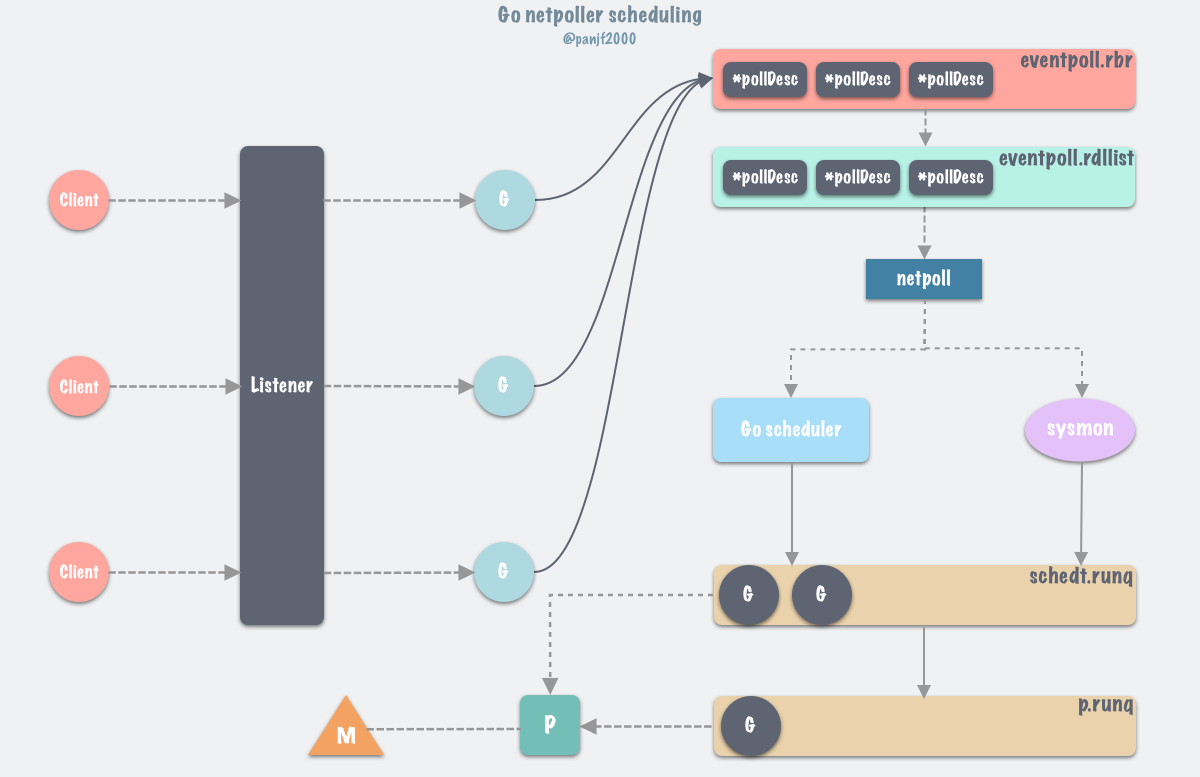
首先,client 连接 server 的时候,listener通过 accept调用接收新 connection,每一个新connection都启动一个goroutine处理,accept调用会把该connection的fd连带所在的 goroutine上下文信息封装注册到epoll的监听列表里去
当goroutine调用conn.Read或者 conn.Write等需要阻塞等待的函数时,会被gopark给封存起来并使之休眠,让 P 去执行本地调度队列里的下一个可执行的 goroutine。通过调用gopark,goroutine会被放置在某个等待队列中,这里是放到了epoll的由红黑树实现的 eventpoll.rbr,此时 G 的状态由Grunning变为Gwaitting。
golang如何建立文件描述符和goroutine之间的关联? pollDesc结构体就是完成这个任务的
1 | |
gopark函数在协程的实现上扮演着非常重要的角色,用于协程的切换,gopark函数做的主要事情分为两点:
- 解除当前goroutine的m的绑定关系,将当前goroutine状态机切换为等待状态;
- 调用一次schedule()函数,在局部调度器P发起一轮新的调度。
gopark源码中最重要的就是
mcall(park_m)函数,这个函数会切换当前线程的堆栈从g的堆栈切换到g0的堆栈,并保存当前协程的信息
Go scheduler会在循环调度的runtime.schedule() 函数以及 sysmon监控线程中调用 runtime.netpoll以获取可运行的goroutine列表
和epoll的逻辑一样,runtime.netpoll里会调用epoll_wait从 epoll 的 eventpoll.rdllist就绪双向链表返回,从而得到 I/O 就绪的 socket fd 列表,并根据取出最初调用 epoll_ctl 时保存的上下文信息,恢复 g
所以执行完netpoll之后,会返回一个就绪fd列表对应的 goroutine链表,接下来将就绪的goroutine通过调用injectglist加入到全局调度队列或者P的本地调度队列中,启动M绑定P去执行。
Go runtime在程序启动的时候会创建一个独立的M作为监控线程,叫sysmon ,每 20us~10ms 运行一次。
这个线程为系统级的 daemon 线程,无需P即可运行
sysmon中以轮询的方式执行以下操作:
- 以非阻塞的方式调用runtime.netpoll ,从中找出能从网络 I/O 中唤醒的G列表,并通过调用 injectglist 把 G 列表放入全局调度队列或者当前 P 本地调度队列等待被执行,调度触发时,有可能从这个全局 runnable 调度队列获取 g。然后再循环调用 startm ,直到所有 P 都不处于 _Pidle 状态。
- 调用 retake ,抢占长时间处于 _Psyscall 状态的 P。
和使用Unix系统中的select或是epoll不同地是,Golang的netpoller查询的是能被调度的goroutine而不是那些函数指针、包含了各种状态变量的struct等,这样你就不用管理这些状态,也不用重新检查函数指针等,这些都是你在传统Unix网络I/O需要操心的问题。