netty基础
为什么我们不用Java NIO?
原生的Java NIO编程,对编程能力要求比较高,需要处理连接异常、网络闪断、拆包粘包、网络拥塞、长短连接等各种各样的网络通讯细节问题,这是一件非常困难且耗时的事情。并且,原生Java NIO还有一个臭名昭著的Epoll Bug,它会导致Selector空轮询,最终导致CPU 100%。官方声称在JDK 1.6版本的update 18修复了该问题,但是直到JDK1.7版本该问题仍旧存在,只不过该Bug发生概率降低了一些而已,它并没有被根本解决。
Netty和Tomcat有什么区别?
Netty是一个基于NIO的异步网络通信框架,性能高,封装了原生NIO,降低了编码复杂度。
Tomcat是一个Web服务器,是一个Servlet容器,内部只运行Servlet程序并处理HTTP请求。
Netty封装的是IO模型,用于处理网络数据的传输,不关心具体的协议,其定制性更高
Reactor模式
Reactor模式本质是一种事件驱动模型,由两部分组成
- Reactor反应器线程:负责查询IO事件,当检测到一个IO事件,将其发送给相应的Handler处理器去处理。这里的IO事件,就是NIO中Selector监控的通道IO事件;
- Handlers处理器:与IO事件(或者选择键)绑定,负责IO事件的处理,完成真正的连接建立、通道读取、处理业务逻辑、将结果写入通道等操作。
单Reactor单线程模式
单Reactor单线程模式,是指Reactor反应器和Handers处理器处于一个线程中执行。这种模式下,Reactor线程是个多面手,负责多路分离套接字,accept新连接,并分派请求到处理器链中:
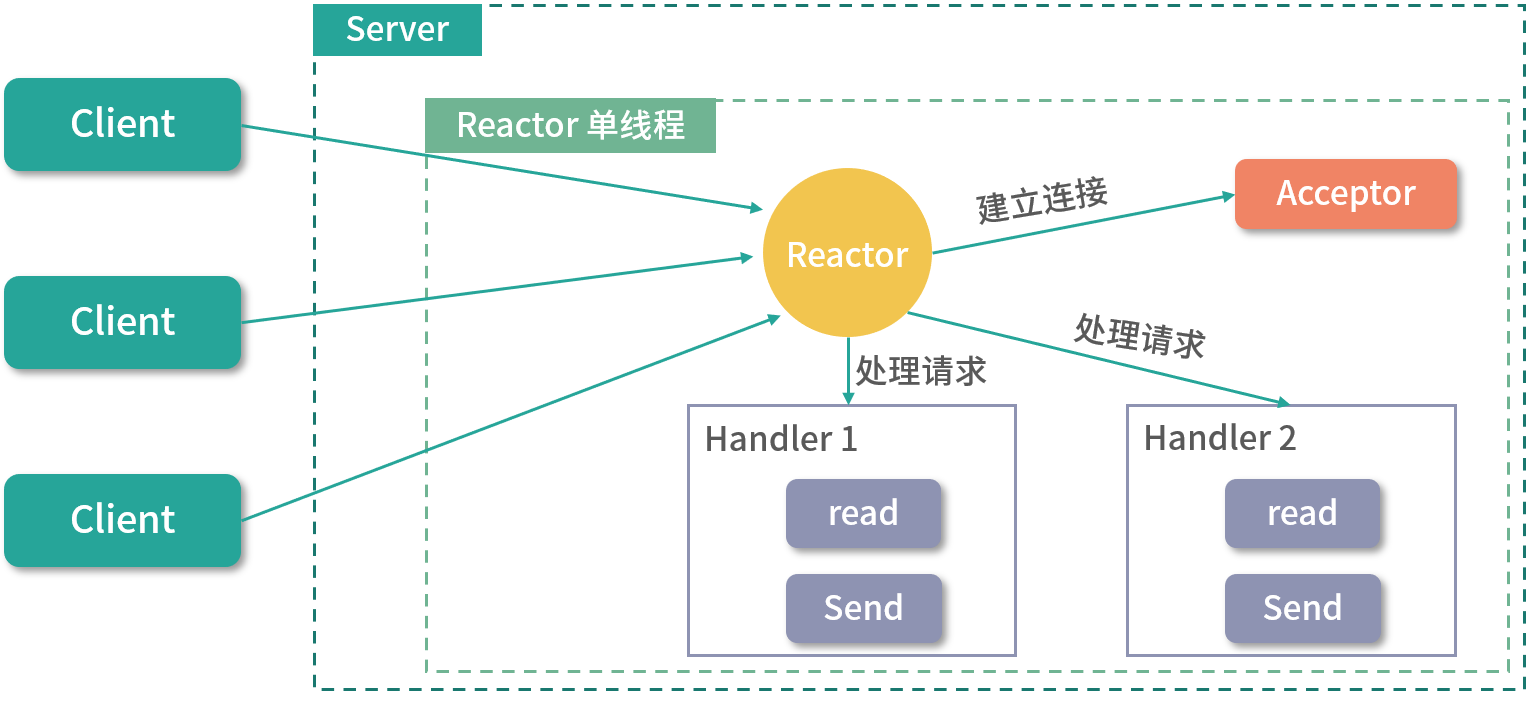
单reactor-多线程
有一个专门的NIO线程用于监听服务端,接收客户端的TCP连接请求;
网络读写等I/O操作由一个NIO线程池负责,线程池可以采用标准的JDK线程池实现,它包含一个任务队列和N个可用的线程,由这些NIO线程负责消息的读取、解码、编码和发送;
1个acceptor线程可以同时处理N条链路,但是1个链路只对应1个NIO线程,防止发生并发操作问题。
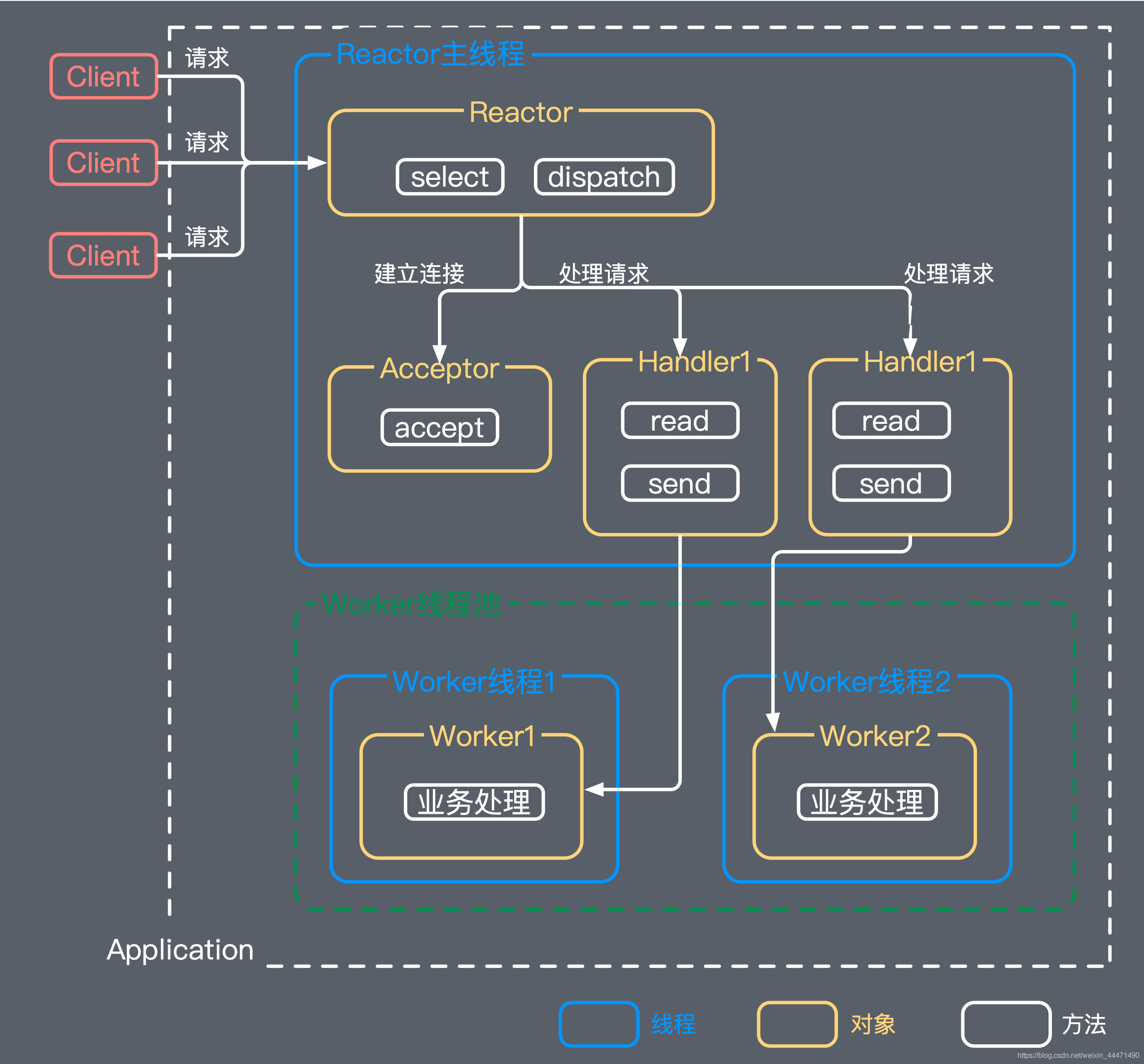
主从reactor-多线程
服务端不再只用一个Acceptor线程接收客户端连接,而是一个独立的MainReactor线程池
主从Reactor多线程模式比起单Reactor多线程模式,是将Reactor分成两部分:
- mainReactor:负责监听ServerSocket,accept新连接,并将建立的Socket分派给subReactor。
- subReactor:负责多路分离已连接的Socket,读写网络数据,并交给worker线程池处理。
mainReactor线程池中的每个线程都可以接收客户端的TCP连接请求,并将建立完连接后的SocketChannel交给subReactor线程池处理;
subReactor线程池中的线程会将接收到的SocketChannel注册到自己的Selector上,并负责监听和处理该SocketChannel的读/写事件;
mainReactor线程池只用于客户端的登录、握手和安全认证,一旦链路建立成功,就将链路注册到后端subReactor线程池的线程上,由它们负责后续的I/O操作。
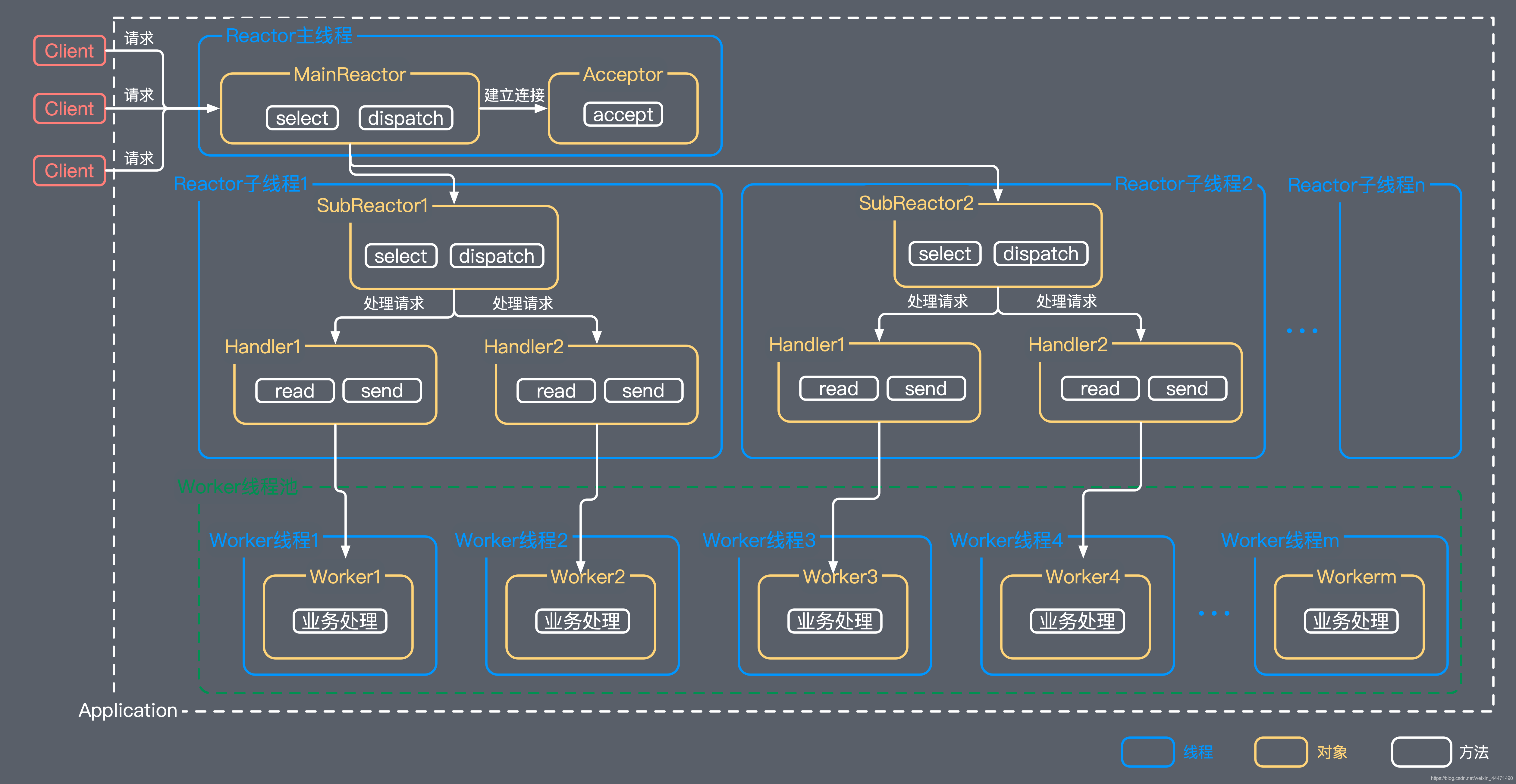
Netty结构
Channel
在Netty中,通道(Channel)是核心概念之一,代表着网络连接。
Channel负责与对端进行网络通信:既可以写入数据到对端,也可以从对端读取数据。
Netty没有直接使用Java NIO的Channel通道,而是自己对Channel通道进行了封装。对应于不同的协议,Netty中常见的通道类型如下:
NioSocketChannel:TCP Socket传输通道;
NioServerSocketChannel:TCP Socket服务器端监听通道;
Handler
在Netty中,Handler是核心的业务处理组件,从开发人员的视角看,有入站和出站两种类型。
入站:触发的方向为自底向上,一般都继承ChannelInboundHandler入站处理器。当数据或者信息入站到Netty通道时,Netty将触发ChannelInboundHandler对应的入站API,进行入站操作处理;
出站:触发的方向为自顶向下,一般都继承ChannelOutboundHandler出站处理器。当业务处理完成后,需要操作Java NIO底层通道时,通过一系列的ChannelOutboundHandler出站处理器,完成Netty通道到底层通道的操作。
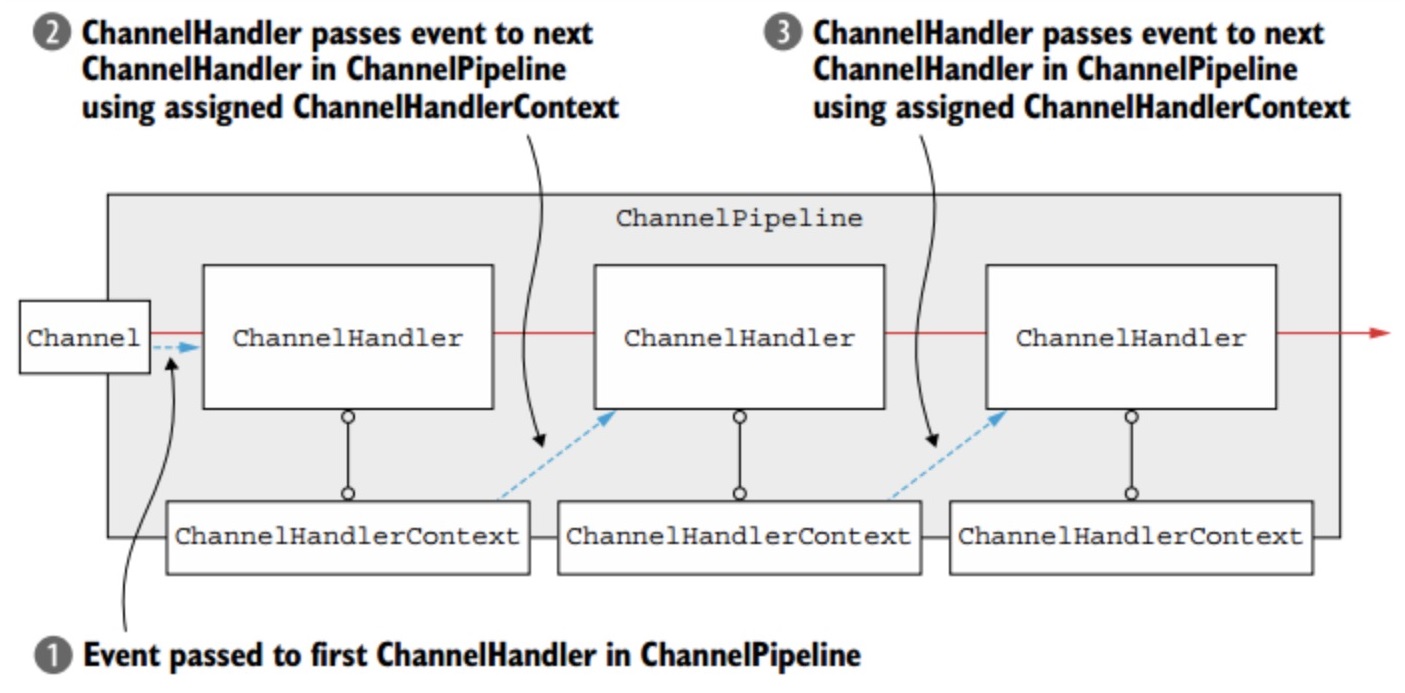
ChannelPipeline
一条Netty通道需要很多的Handler业务处理器来处理业务。每条通道内部都有一条流水线(Pipeline)将Handler装配起来。
Netty的业务处理器流水线ChannelPipeline内部是一个双向链表结构,能够支持动态添加、删除Handler业务处理器。
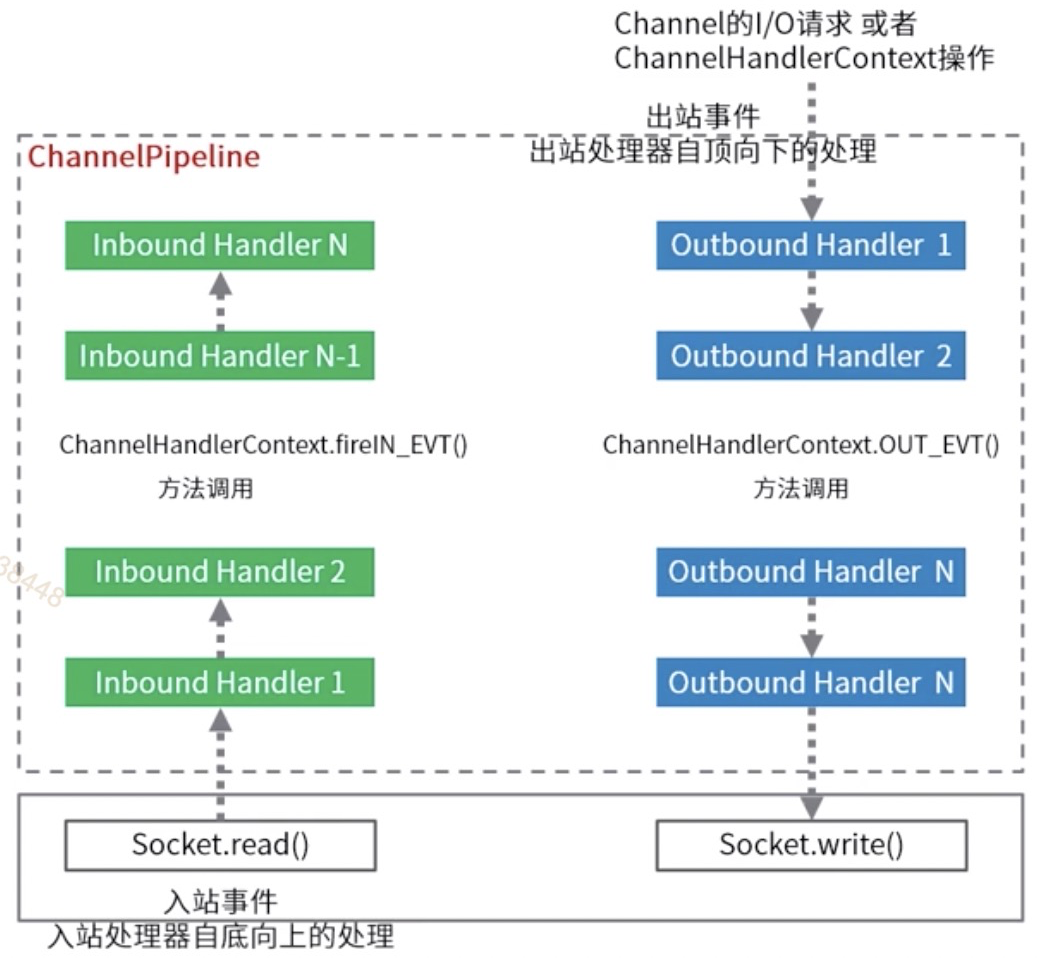
ChannelHandlerContext
在Handler业务处理器被添加到流水线Pipeline中时,会创建一个通道处理器上下文ChannelHandlerContext,它代表了ChannelHandler和ChannelPipeline之间的关联。ChannelHandlerContext中包含了有许多方法,可以通过其获取上下文所关联的Netty组件实例,如所关联的通道、流水线、上下文内部的Handler业务处理器等;
所以,总结一下,Channel、Handler、ChannelHandlerContext三者的关系为:
- 每个Channel通道拥有一条ChannelPipeline通道流水线,流水线节点为ChannelHandlerContext上下文对象,每一个ChannelHandlerContext中包裹了一个ChannelHandler处理器;
- 在ChannelHandler的入站/出站处理方法中,Netty都会传递一个ChannelHandlerContext实例作为参数。在业务处理中,通过ChannelHandlerContext可以获取ChannelPipeline实例或者Channel实例。
ByteBuf
ByteBuf是一个字节容器,内部是一个字节数组。
Netty没有直接使用Java NIO中的ByteBuffer,而是自己是实现了一个BtyeBuf。与Java NIO的ByteBuffer相比,ByteBuf的优势如下:
- Pooling(池化),减少了内存复制和GC,提升了效率;
- 支持自动扩容,使用更方便。
Decoder
解码器:Netty从底层的Java通道读取字节数据,传入Netty通道的流水线中,随后开始入站处理。在入站处理过程中,需要将ByteBuf字节数据,解码成Java POJO对象。这个解码过程,通过Netty的Decoder完成。
所有的Netty中的Decoder解码器,都是Inbound入站处理器类型,都直接或者间接地实现了ChannelInboundHandler接口,负责处理“入站数据”。解码器能将上一站Inbound入站处理器传过来的输入(Input)数据,进行数据的解码或者格式转换,然后输出(Output)到下一站Inbound入站处理器。
Encoder
在Netty的业务处理完成后,业务处理的结果往往是某个Java POJO对象,需要编码成最终的ByteBuf二进制类型,通过流水线写入到底层的Java通道。这个编码过程,通过Netty的Encoder完成。
所有的Netty中的Encoder编码器,都是Outbound出站处理器类型,都直接或者间接地实现了ChannelOutboundHandler接口,负责处理“出站数据”。编码器将上一站Outbound出站处理器传过来的输入(Input)数据进行编码或者格式转换,然后传递到下一站ChannelOutboundHandler出站处理器。
Netty的线程模型是怎么样的
Netty同时支持Reactor单线程模型,多线程模型,主从多线程模型,用户可以配置参数在这三种模型之间切换
服务端启动时,通常会创建两个NioEventLoopGroup实例,对应两个独立的Reactor线程池,bossGroup负责处理客户端的连接请求,workerGroup负责处理IO相关的操作,执行任务等。用户可以根据ServerBootstrap启动类选择参数配置线程模型。
Netty为什么高性能?
- NIO模型,用最少的资源完成最多的任务
- 内存零拷贝,减少不必要的拷贝造成资源浪费,实现更高效率的传输
- 串行化处理读写:消息的处理尽可能在同一个线程内完成,避免切换线程的花销,避免多线程竞争和同步锁。调整NIO线程池的线程参数,可以同时启动多个串行化的线程,相比于多线程竞争机制性能更优。
- 支持protobuf:
protobuf(protocol buffer) 是谷歌内部的混合语言数据标准。通过将结构化的数据进行序列化(串行化),用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。是一个高性能的编解码框架,序列化数据后数据更小,传输速度更快,安全性也更高,netty可以直接在handler内添加protobuf编码解码器。 - 内存池设计,申请的内存可以重用
粘包
现象:发送abc和def,结果接收到abcdef
原因:
- 应用层:接收方的bytebuf设置太大(默认1024)
- TCP滑动窗口足够大,且接收方处理不及时
- TCP的Nagle算法:为了减少广域网的小分组数目,从而减小网络拥塞的出现,会造成粘包。
netty的解决方案:
- 短连接,发完一次消息后便断开连接。下一次发消息的时候再次建立连接,重置了缓冲区
- 设置合理的缓冲区
半包
现象:发送abcdef接收到abc和def
原因:
- 应用层:bytebuf过小
- TCP滑动窗口过小
- 链路层:MSS限制
netty解决方案
FixedLengthFrameDecoder定长帧解码器:固定收到的帧的大小,若收到半包,则延迟交付,直到收到其他消息满足大小,再交付
LineBasedFrameDecoder行帧解码器:根据特定字符来区分完整的信息,避免半包
LengthFiledBasedFrameDecoder :指定内容长度,偏移量,从第几个字节开始读,跳过几个字节再读,从而精准读取内容避免半包
零拷贝
零拷贝(zero-copy),是指在计算机执行IO操作时,CPU 不需要先将数据从一个内存区域复制到另一个内存区域。具体来讲,就是数据从网络设备到用户程序空间传递的过程中,减少数据拷贝次数,减少系统调用,实现 CPU 的零参与,彻底消除 CPU 在这方面的负载。
传统的Linux I/O模式
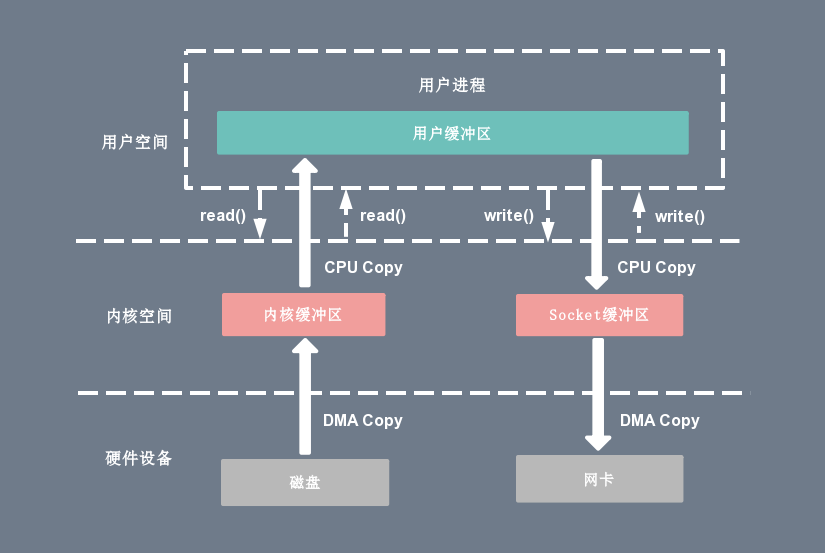
shell read(file_fd, tmp_buf, len); write(socket_fd, tmp_buf, len);
- 用户进程通过
read函数向内核(kernel)发起系统调用,CPU 将用户进程从用户态切换到内核态; - CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer);
- CPU 将读缓冲区中的数据拷贝到用户空间(user space)的用户缓冲区(user buffer);
- CPU 将用户进程从内核态切换回用户态,
read调用执行返回; - 用户进程通过
write函数向内核发起系统调用,CPU 将用户进程从用户态切换到内核态; - CPU 将用户缓冲区中的数据拷贝到内核空间的网络缓冲区(socket buffer);
- CPU 利用 DMA 控制器将数据从网络缓冲区拷贝到网卡,进行数据传输;
- CPU 将用户进程从内核态切换回用户态,
write调用执行返回。
数据必须经过用户缓冲区才能到达Socket缓冲区,虽然加入了DMA来处理内核与硬件的数据传输,但是仍然效率不高
由mmap实现用户态直接I/O
tmp_buf = mmap(file_fd, len);write(socket_fd, tmp_buf, len);
使用 mmap 的目的是将内核中读缓冲区(read buffer)的地址与用户空间的缓冲区(user buffer)进行映射,从而实现内核缓冲区与应用程序内存的共享,省去了将数据从内核读缓冲区(read buffer)拷贝到用户缓冲区(user buffer)的过程,CPU直接将内核缓冲区中的数据拷贝到Socket缓冲区,节省了一次CPU拷贝。
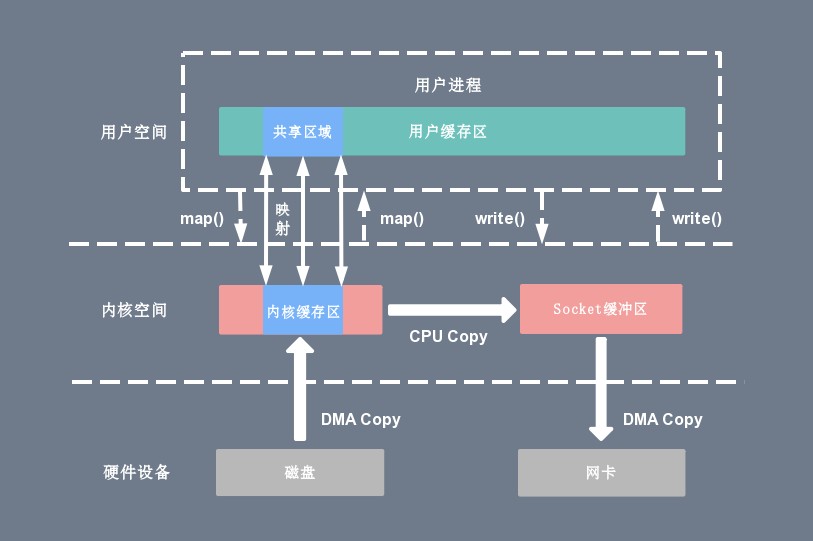
当mmap一个文件时,如果这个文件被另一个进程所截获,那么write系统调用会因为访问非法地址被SIGBUS信号终止,SIGBUS默认会杀死进程并产生一个 coredump,服务器可能因此被终止。
Sendfile实现内核内的数据传输
sendfile(socket_fd, file_fd, len);
通过 Sendfile 系统调用,数据可以直接在内核空间内部进行 I/O 传输,省去了数据在用户空间和内核空间之间的来回拷贝。
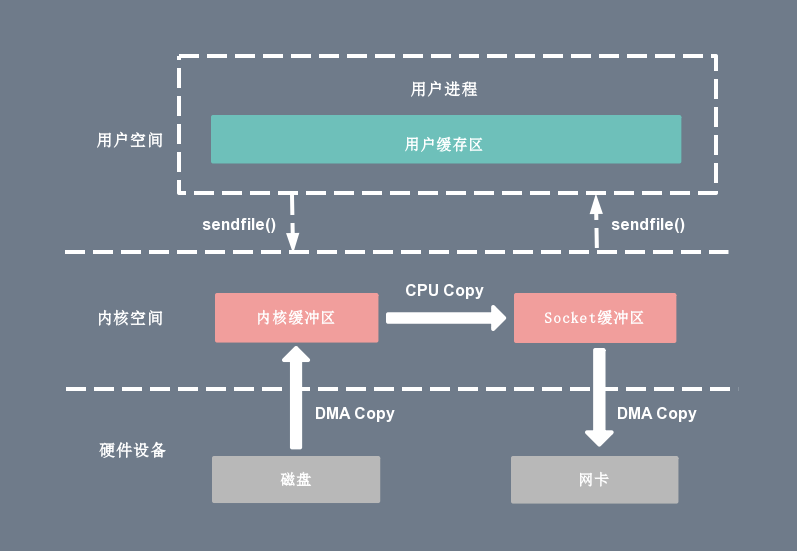
基于 Sendfile 系统调用的零拷贝方式,整个拷贝过程会发生2次上下文切换,1 次CPU拷贝和2次DMA拷贝。
Sendfile 存在的问题是:用户程序不能在中途对数据进行修改,而只是单纯地完成了一次数据传输过程,它只适用于将数据从文件拷贝到 Socket 套接字上的传输过程。
Sendfile+DMA gather copy实现硬件级的直接拷贝
Linux内核2.4版本,对 Sendfile 系统调用进行了修改,为DMA拷贝引入了gather操作:它将内核空间的读缓冲区中对应的数据描述信息(内存地址、地址偏移量)记录到相应的网络缓冲区( socket buffer)中,由 DMA 根据内存地址、地址偏移量将数据批量地从读缓冲区拷贝到网卡设备中。
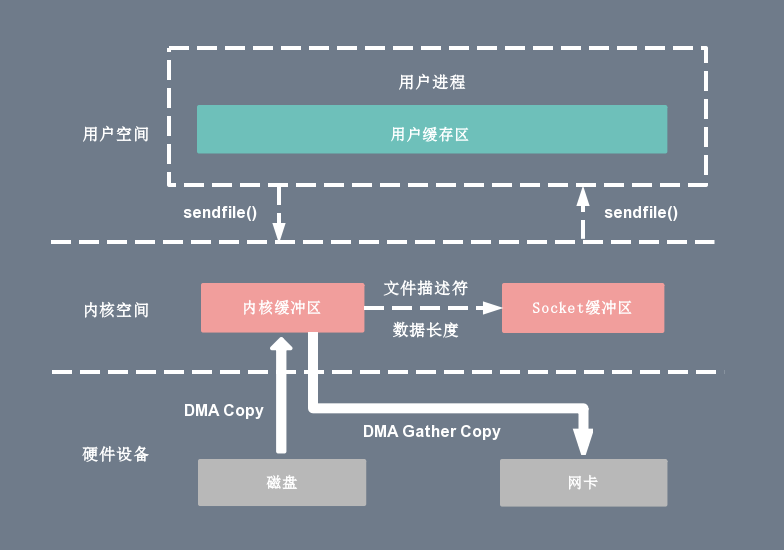
DMA gather copy需要硬件的支持,Sendfile 拷贝方式不再从内核缓冲区的数据拷贝到 Socket 缓冲区,取而代之是仅仅拷贝缓冲区文件描述符和数据长度。
这样 DMA 引擎直接利用 gather 操作将页缓存中数据打包发送到网络中即可,本质是和虚拟内存映射类似的思路
整个拷贝过程会发生2次上下文切换、0次CPU拷贝以及2次 DMA拷贝。
Splice实现管道传输
Linux内核2.6.17版本,引入了 Splice 系统调用。Splice 系统调用可以在内核空间的读缓冲区和网络缓冲区之间建立管道(pipeline),从而避免了两者之间的 CPU 拷贝操作。
Splice 系统调用不仅不需要硬件支持,还实现了两个文件描述符之间的数据零拷贝。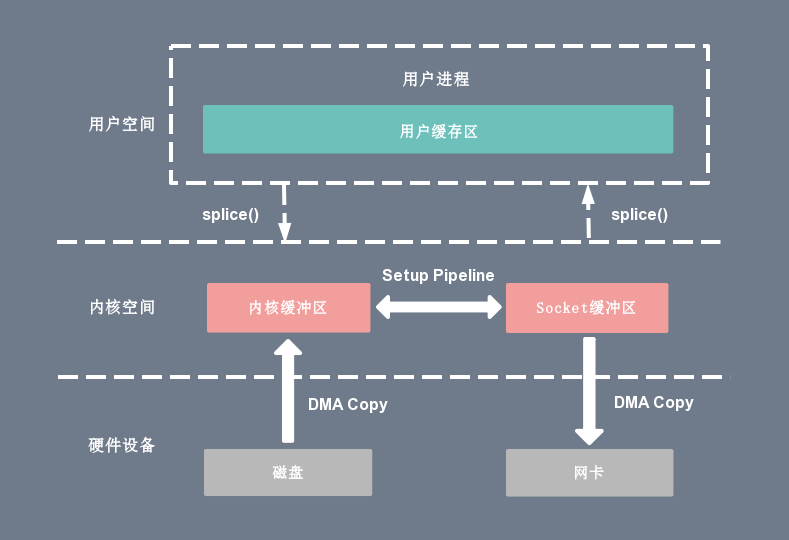
整个拷贝过程会发生2次上下文切换,0次CPU拷贝以及2次DMA拷贝
| 消息队列 | 零拷贝方式 | 优点 | 缺点 |
|---|---|---|---|
| RocketMQ | mmap + write | 适用于小块文件传输,频繁调用时,效率很高 | 不能很好的利用DMA方式,会比sendfile多消耗CPU,内存安全性控制复杂,需要避免JVM Crash问题 |
| Kafka | sendfile | 可以利用DMA方式,消耗CPU较少,大块文件传输效率高,无内存安全性问题 | 小块文件效率低于mmap方式,只能是BIO方式传输,不能使用NIO方式 |
无论是传统 I/O 拷贝方式还是引入零拷贝的方式,2次DMA拷贝都是少不了的,因为两次 DMA 都是依赖硬件完成的
netty的零拷贝
Netty 中也使用了零拷贝技术,但是和操作系统层面上的零拷贝不太一样, Netty 零拷贝是相对于堆内存与堆外内存而言的,它的更多的是偏向于数据操作优化这样的概念。
- Netty接收和发送ByteBuffer采用DirectBuffer,使用堆外直接内存进行Socket读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的JVM的堆内存进行socker读写,那么JVM将会将堆内存拷贝一份到直接内存中,然后在写入socket中。相比堆外直接内存,消息在发送过程中多了一次缓存区的拷贝
- Netty提供CompositeByteBuf组合缓冲区类,可以将多个 ByteBuf合并为一个逻辑上的ByteBufer,避免了各个ByteBufer之间的拷贝,将几个小buffer合并成一个大buffer的繁琐操作。
- Netty提供了ByteBuf的浅层复制操作(slice、 duplicate),可以将ByteBuf分解为多个共享同一个存储区域的 ByteBuf,避免内存的拷贝
- Netty进行文件传输时,可以调用FileRegion包装的 **transferTo()**方法直接将文件缓冲区的数据发送到目标通道,避免普通的循环读取文件数据和写入通道所导致的内存拷贝问题。
- 在将一个byte数组转换为一个ByteBuf对象的场景下,Netty 提供了一系列的包装类,避免了转换过程中的内存拷贝。