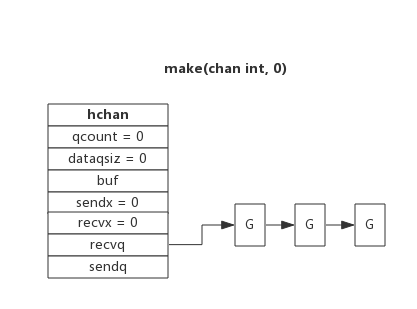
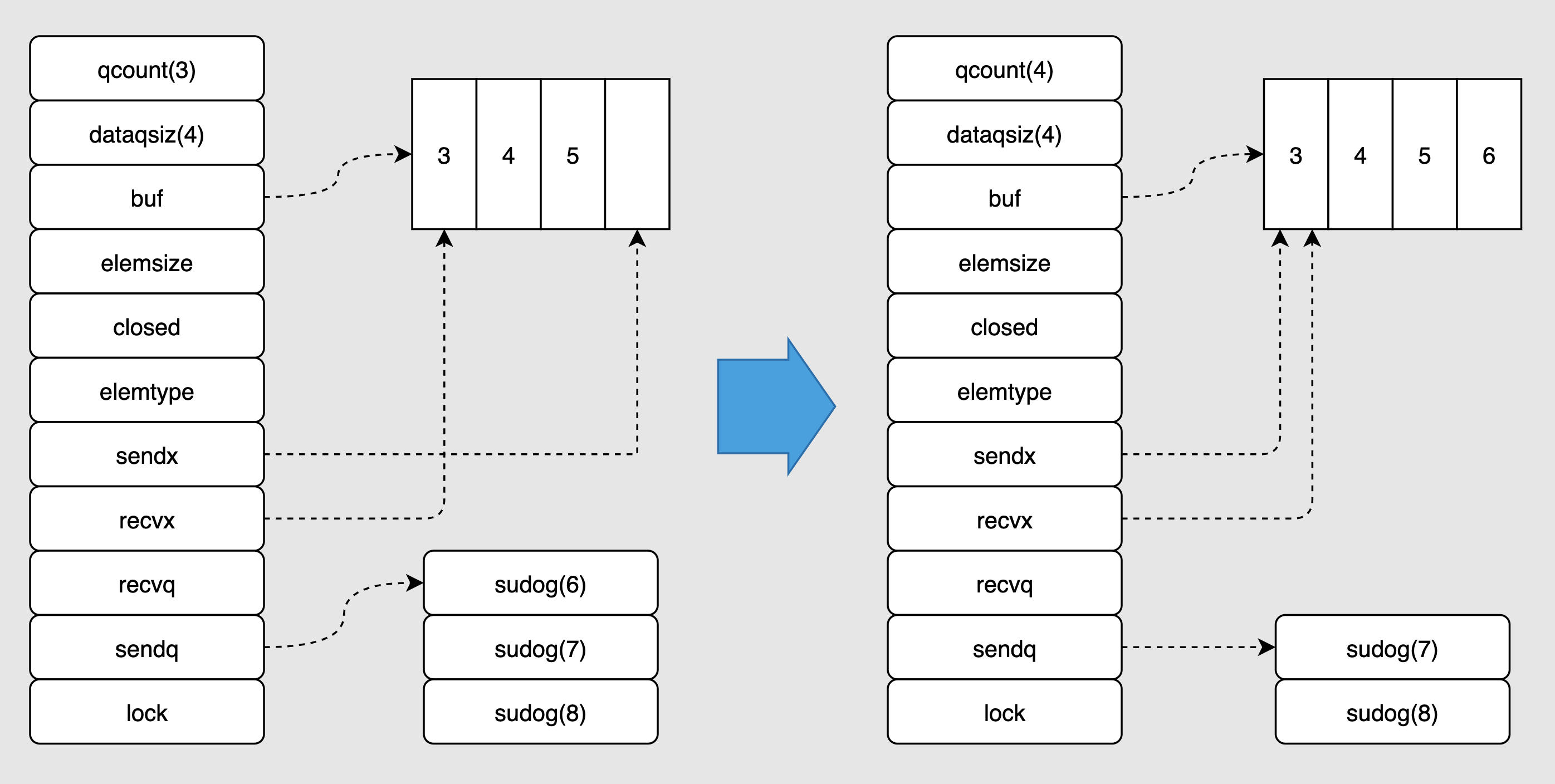
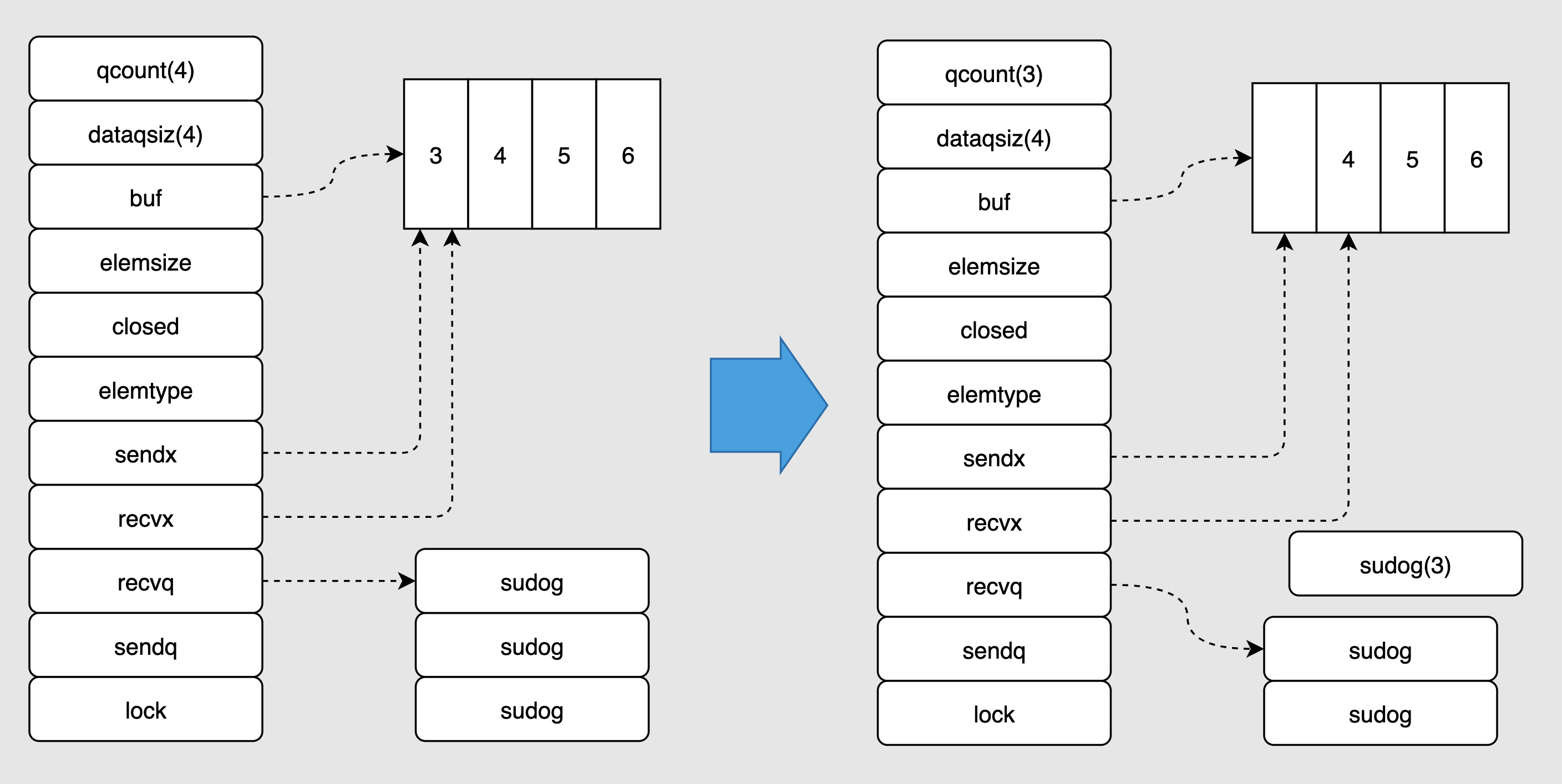
//单向写通道 funcproducer(out chan <- int) { for i := 0; i < 10; i++ { fmt.Println("producer send", i * i) out <- i * i } close(out) } //单向读通道 funcconsumer(in <- chanint) { for num := range in { fmt.Println("consumer recv", num) } }
// 计算1000个数的和 funccompute(m *sync.Mutex, wg *sync.WaitGroup, s, e int, count *int) { sum := 0 for i := s; i < e; i++ { sum += i } m.Lock() *count += sum m.Unlock() //每个协程执行结束最后都会执行一次 Done() 函数,表示当前协程完成 wg.Done() }
funcmain() {
var m sync.Mutex //声明wg var wg sync.WaitGroup
var count int //因为这里开了1000个协程,所以执行 Add(1000) wg.Add(1000) for i := 0; i < 1000; i++ { go compute(&m, &wg, i*1000+1, (i+1)*1000+1, &count) } //执行 Wait() 函数,等待这1000个协程组完成任务 wg.Wait() fmt.Println(math.Sqrt(float64(count))) return }
实现原理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
type WaitGroup struct { noCopy noCopy
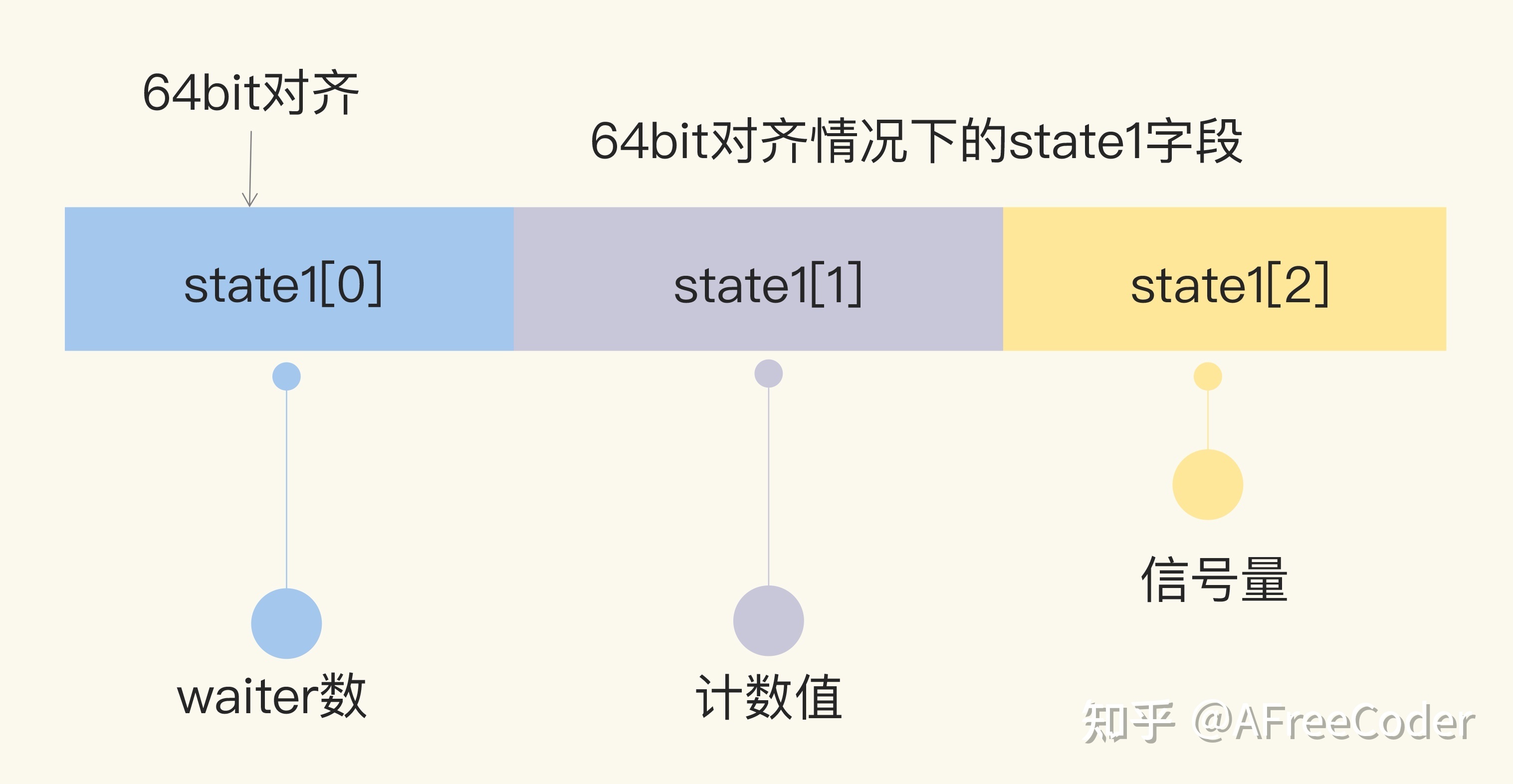
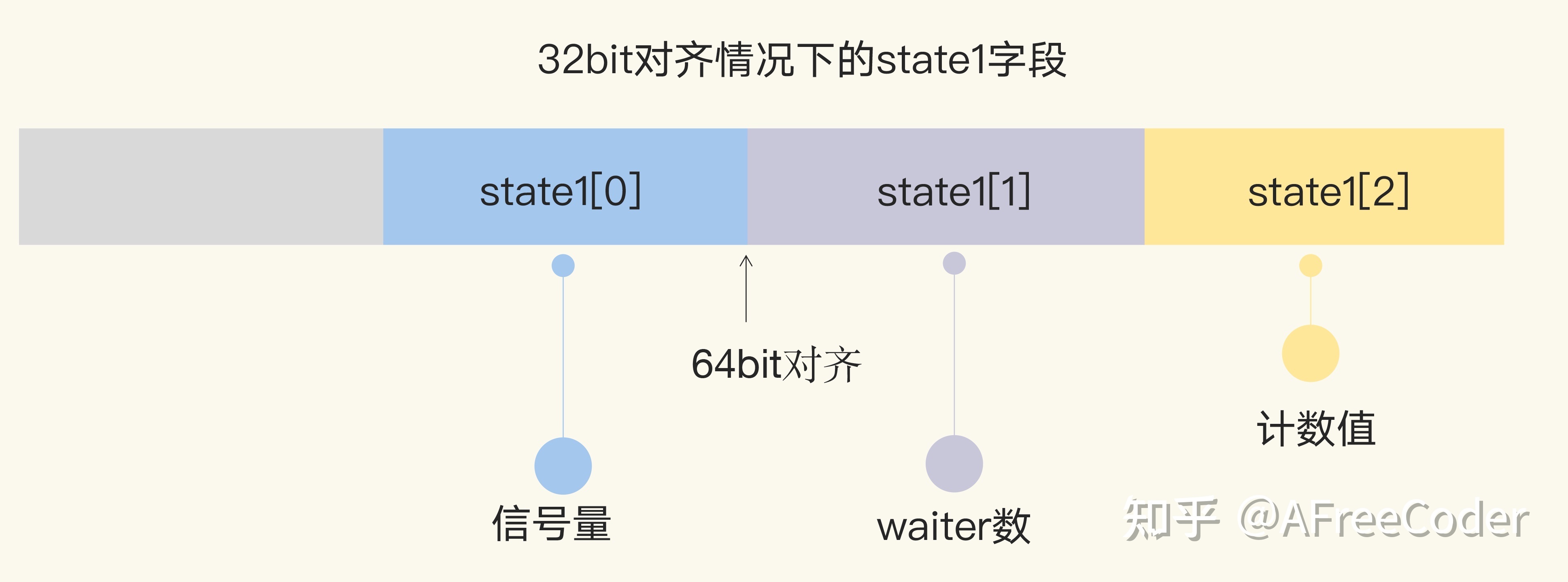
// 64-bit value: high 32 bits are counter, low 32 bits are waiter count. // 64-bit atomic operations require 64-bit alignment, but 32-bit // compilers do not ensure it. So we allocate 12 bytes and then use // the aligned 8 bytes in them as state, and the other 4 as storage // for the sema. state1 [3]uint32 }
// state returns pointers to the state and sema fields stored within wg.state1. func(wg *WaitGroup) state() (statep *uint64, semap *uint32) { ifuintptr(unsafe.Pointer(&wg.state1))%8 == 0 { return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2] } else { return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0] } }