Spring
bean的生命周期
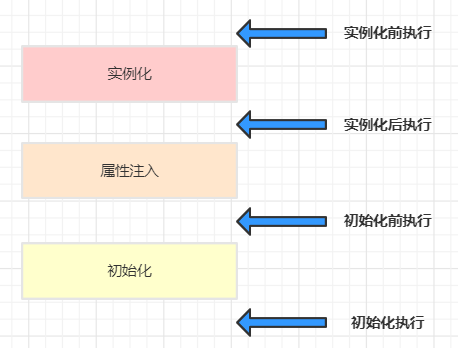
Bean的创建分为三个基本步骤
- 实例化:可以理解为new一个对象,
AbstractAutowireCapableBeanFactory中的createBeanInstance方法 - 属性注入:可以理解为setter方法完成属性注入,
AbstractAutowireCapableBeanFactory的populateBean方法 - 初始化:按照Spring的规则配置一些初始化的方法,例如实现AOP代理,注解。
AbstractAutowireCapableBeanFactory的initializeBean方法
而Bean的完整生命周期就是在上面三个步骤中穿插执行BeanPostProcessor后置处理器的过程
普通Java对象可以理解为它是用Class对象作为「模板」进而创建出具体的实例,而Spring所管理的Bean不同的是,除了Class对象之外,还会使用BeanDefinition的实例来描述对象的信息,比如说,我们可以在Spring所管理的Bean有一系列的描述:@Scope、@Lazy等等。可以理解为:Class只描述了类的信息,而BeanDefinition描述了对象的信息。
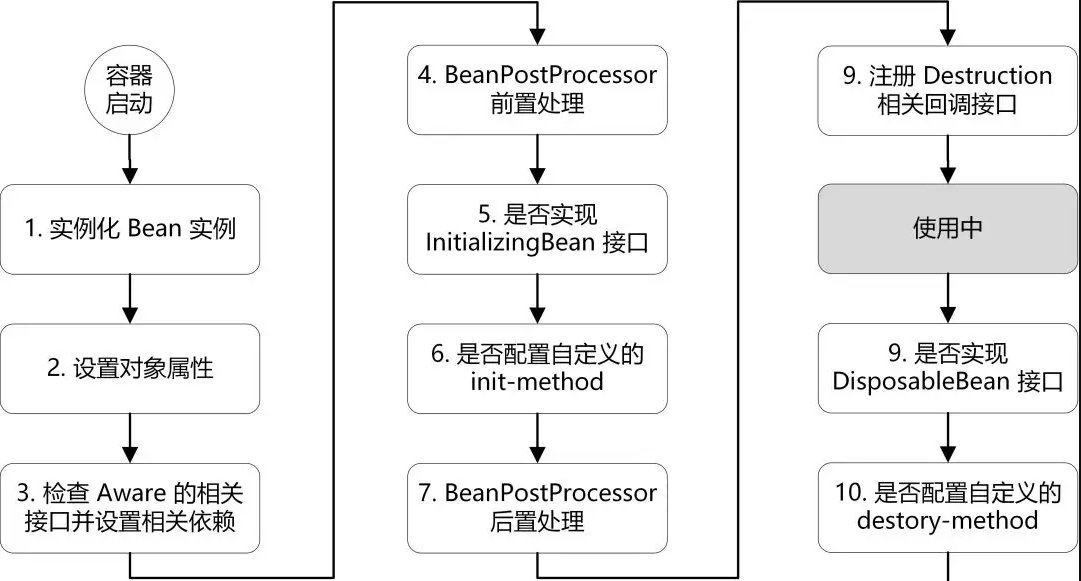
Spring在启动的时候需要「扫描」在XML/注解/JavaConfig 中需要被Spring管理的Bean信息,随后,会将这些信息封装成BeanDefinition,最后会把这些信息放到一个beanDefinitionMap中,key是beanName,value则是BeanDefinition对象,目前真实对象还没实例化,接着会遍历这个beanDefinitionMap,执行BeanFactoryPostProcessor这个Bean工厂后置处理器
比如说,我们平时定义的占位符信息,就是通过BeanFactoryPostProcessor的子类PropertyPlaceholderConfigurer进行注入进去,我们也可以自定义BeanFactoryPostProcessor来对我们定义好的Bean元数据进行获取或者修改
BeanFactoryPostProcessor后置处理器执行完了以后,就到了实例化对象,在Spring里边是通过反射来实现的,一般情况下会通过反射选择合适的构造器来把对象实例化
1 | |
实例化只是把对象给创建出来,而对象具体的属性是还没注入的,比如我的对象是UserService,而UserService对象依赖着SendService对象,这时候的SendService还是null的,使用populateBean()进行属性注入,这里便会牵扯出循环依赖的问题
属性注入后会判断该Bean是否实现了Aware相关的接口,如果存在则填充相关的资源,invokeAwareMethod(),进行BeanName,BeanFactory,BeanClassLoader属性设置
Aware相关的接口处理完之后,就会到BeanPostProcessor后置处理器,BeanPostProcessor后置处理器有两个方法,一个是before,一个是after
BeanPostProcessor相关子类的before方法执行完,则执行init相关的方法,比如说@PostConstruct、实现了InitializingBean接口、定义的init-method方法
init方法执行完之后,就会执行BeanPostProcessor的after方法,AOP就在此实现(关键子类AnnotationAwareAspectJAutoProxyCreator),基本重要的流程已经走完了,我们就可以获取到对象去使用了
对IOC的理解
控制反转:一种编程思想,即讲对象交给spring容器来帮我们进行管理。
DI:依赖注入,把对应的值注入到具体的对象中,即@Autowired或者populateBean
容器:存放对象,使用Map结构来存储,在spring中一般存在三级缓存,singletonObject存放完整的Bean对象,bean的整个生命周期,从创建到销毁都是由容器来管理。
AOP是如何实现的
AOP是IOC的一个扩展功能,现有IOC,再有AOP,AOP是IOC整个流程的一个扩展点
- advice:切面的工作被描述为通知
- Joinpoint:动态代理所代理实现类中的各个方法称为连接点
- Pointcut:代理类中真正增强的方法
- Aspect:将通知用到切入点的过程叫切面
在bean的创建过程中有一个步骤可以对bean进行扩展实现,beanPostProcessor后置处理,而AOP就是其中一个扩展
- 代理对象的创建(advice,切面,切点)
- 通过JDK或者CGLIB的方式来生成代理对象
- 在执行方法调用的时候,会调用到生成的字节码文件中,会调用DynamicAdvisoredInterceptor类中的intercept方法,从此方法开始执行
- 根据之前定义好的通知生成拦截器
- 按照拦截器链中以此获取每一个通知,开始进行执行
循环依赖和三级缓存
所谓的循环依赖,就是两个或则两个以上的bean互相依赖对方,最终形成闭环
比如“A对象依赖B对象,而B对象也依赖A对象”,或者“A对象依赖B对象,B对象依赖C对象,C对象依赖A对象”
1 | |
在常规情况下,会出现以下情况
- 通过构建函数创建A对象(A对象是半成品,还没注入属性和调用init方法)。
- A对象需要注入B对象,发现对象池里还没有B对象(对象在创建并且注入属性和初始化完成之后,会放入对象缓存里)。
- 通过构建函数创建B对象(B对象是半成品,还没注入属性和调用init方法)。
- B对象需要注入A对象,发现对象池里还没有A对象。
- 创建A对象,循环以上步骤。
解决循环依赖的最核心思想:提前曝光
将半成品A提前放入缓存池,从而可以让B对象成功完成属性注入和初始化,成品B可以让半成品A完成初始化,从而打破了循环依赖
- 通过构建函数创建A对象(A对象是半成品,还没注入属性和调用init方法)。
- A对象需要注入B对象,发现缓存里还没有B对象,将
半成品对象A放入半成品缓存。 - 通过构建函数创建B对象(B对象是半成品,还没注入属性和调用init方法)。
- B对象需要注入A对象,从
半成品缓存里取到半成品对象A。 - B对象继续注入其他属性和初始化,之后将
完成品B对象放入完成品缓存。 - A对象继续注入属性,从
完成品缓存中取到完成品B对象并注入。 - A对象继续注入其他属性和初始化,之后将
完成品A对象放入完成品缓存。
三级缓存
1 | |
直接看流程图:
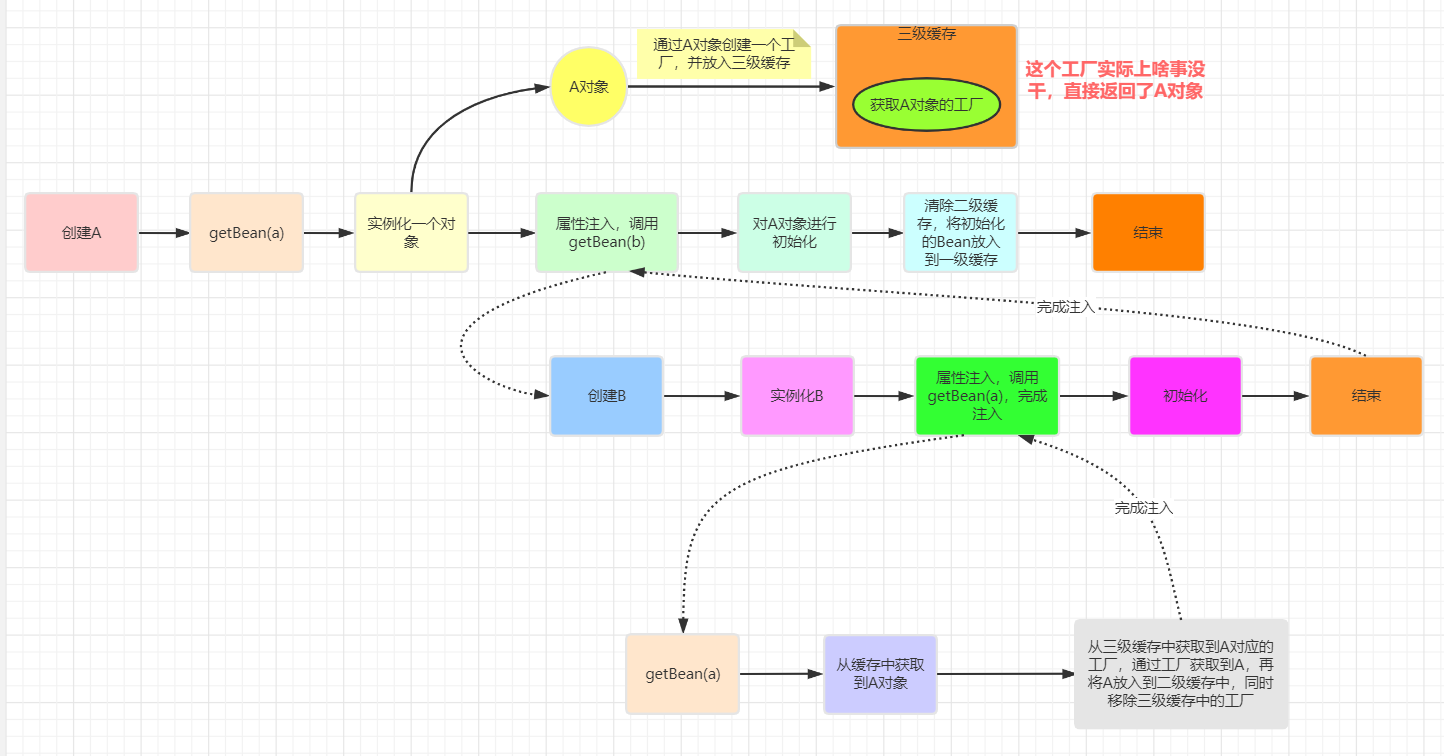
问:这里的第三级缓存有什么用?
如果我们不考虑AOP的情况下,第三级缓存真没什么用,它直接将实例化阶段创建的对象给返回了。
如果我们考虑上了AOP,那么流程图会变成:
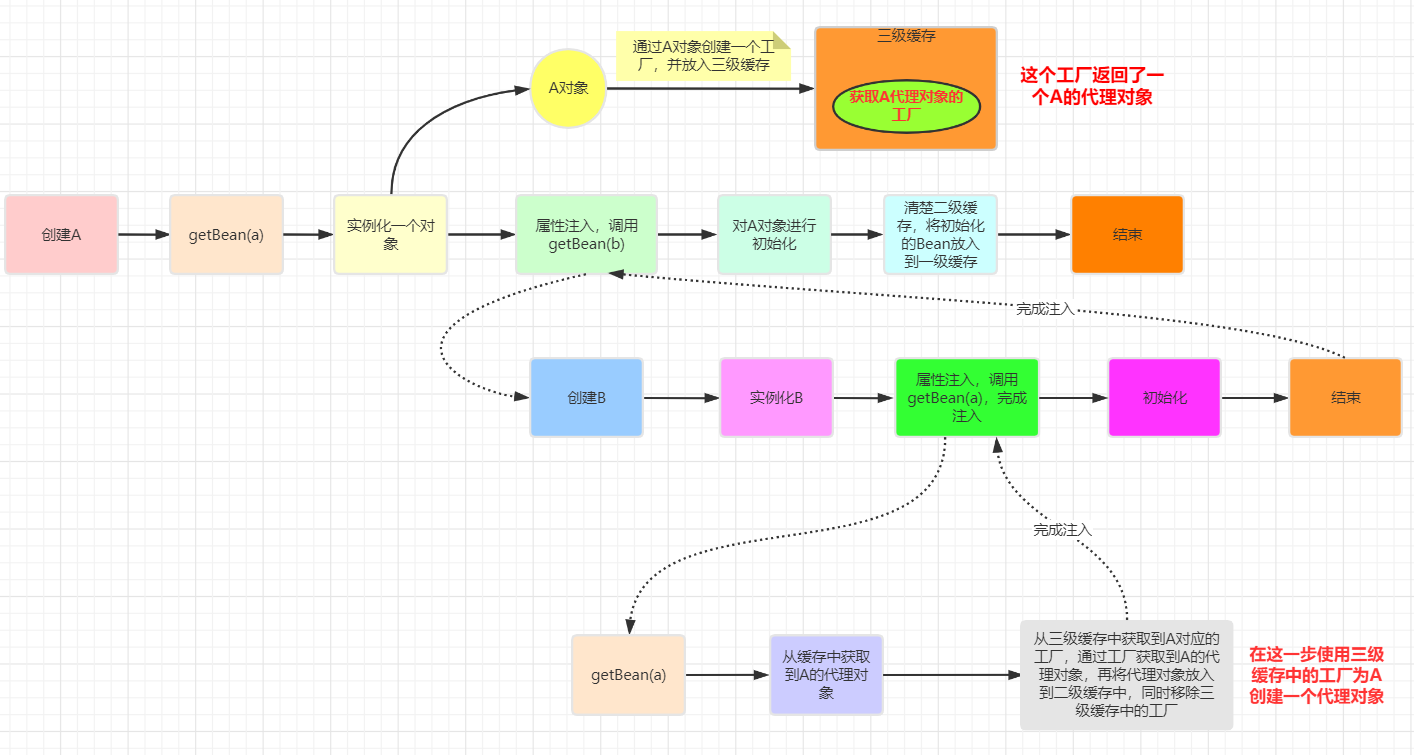
我们对A进行了AOP代理的话,那么此时getEarlyBeanReference将返回一个代理后的对象,而不是实例化阶段创建的对象,这样就意味着B中注入的A将是一个代理对象而不是A的实例化阶段创建后的对象。
问:初始化的时候是对A对象本身进行初始化,而容器中以及注入到B中的都是代理对象,这样不会有问题吗?
不会,这是因为不管是cglib代理还是jdk动态代理生成的代理类,内部都持有一个目标类的引用,当调用代理对象的方法时,实际会去调用目标对象的方法,A完成初始化相当于代理对象自身也完成了初始化。
问:三级缓存为啥要存一个工厂,而不是直接存一个引用进去呢?
工厂的目的在于只有真正发生循环依赖的时候,才会去生成代理对象。如果未发生循环依赖,那么就只有一个工厂放那儿,但是不会去通过这个工厂去真正创建对象。
问:为什么要使用第三级缓存呢,不管有没有循环依赖,我们都提前创建好代理对象,并将代理对象放入缓存,出现循环依赖时,其他对象直接就可以取到代理对象并注入。这样就只会使用两级缓存,不是更方便嘛?
如果要使用二级缓存解决循环依赖,意味着Bean在构造完后就需要创建代理对象,这样违背了Spring设计原则!!
Spring结合AOP跟Bean的生命周期,是在Bean创建完全之后通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来完成的,在这个后置处理的postProcessAfterInitialization方法中对初始化后的Bean完成AOP代理。如果出现了循环依赖,那没有办法,只有给Bean先创建代理,但是没有出现循环依赖的情况下,设计之初就是让Bean在生命周期的最后一步完成代理而不是在实例化后就立马完成代理。
使用二级缓存:
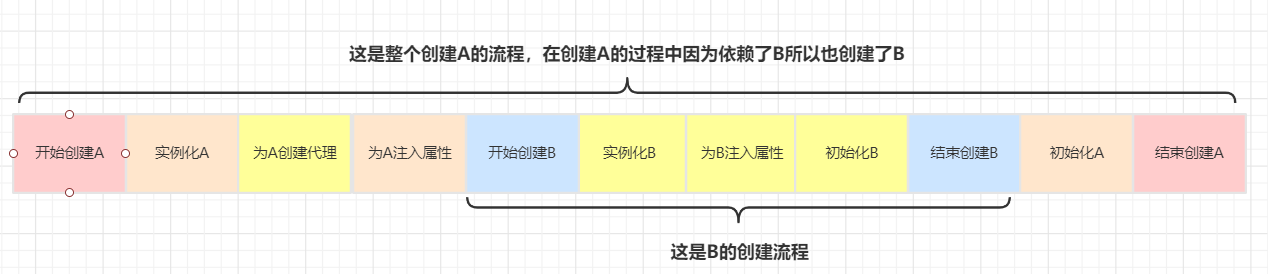
使用三级缓存:
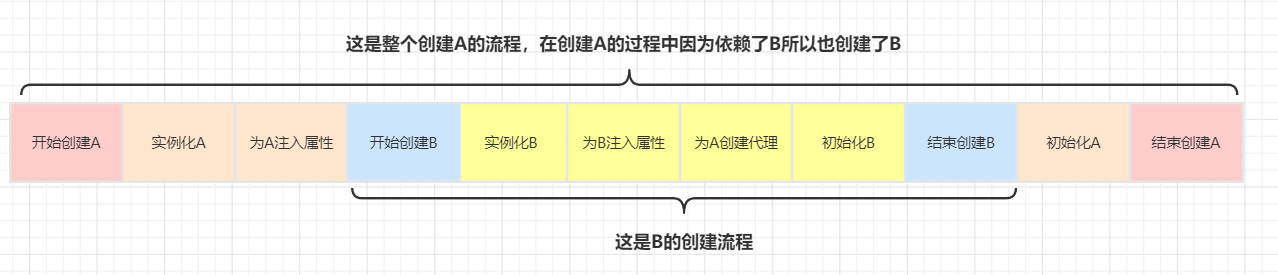
总结:Spring如何解决循环依赖?
答:Spring通过三级缓存解决了循环依赖,其中一级缓存为单例池(singletonObjects,一个并发HashMap),二级缓存为早期曝光对象earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories),二三级缓存均为普通的HashMap。
当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,并添加到三级缓存中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化的对象。
当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用getBean(a)来获取需要的依赖,此时的getBean(a)会从缓存中获取,第一步,先获取到三级缓存中的工厂;第二步,调用对象工工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中。紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。
当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束!
JDK和CGLIB动态代理的区别
JDK代理使用的是反射机制生成一个实现代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理。
CGLIB代理使用字节码处理框架ASM,对代理对象类的class文件加载进来,通过修改字节码生成子类。
JDK创建代理对象效率较高,执行效率较低,JDK动态代理机制是委托机制,只能对实现接口的类生成代理,通过反射动态实现接口类。
CGLIB创建代理对象效率较低,执行效率高,CGLIB则使用的继承机制,针对类实现代理,被代理类和代理类是继承关系,所以代理类是可以赋值给被代理类的,因为是继承机制,不能代理final修饰的类。
如果目标对象实现了接口,默认情况下会采用JDK的动态代理实现AOP,可以强制使用CGLIB实现AOP,如果目标对象没有实现了接口,必须采用CGLIB库,spring会自动在JDK动态代理和CGLIB之间转换。
JDK动态代理只能为接口创建代理,使用上有局限性。实际的场景中我们的类不一定有接口,此时如果我们想为普通的类也实现代理功能,我们就需要用到CGLIB来实现了。
JDK代理是不需要依赖第三方的库,只要JDK环境就可以进行代理,需要满足以下要求:
1.实现InvocationHandler接口,重写invoke()
2.使用Proxy.newProxyInstance()产生代理对象
3.被代理的对象必须要实现接口
CGLIB 必须依赖于CGLIB的类库,需要满足以下要求:
1.实现MethodInterceptor接口,重写intercept()
2.使用Enhancer对象.create()产生代理对象
CGLIB是一个强大、高性能的字节码生成库,它用于在运行时扩展Java类和实现接口,本质上它是通过动态的生成一个子类去覆盖所要代理的类(非final修饰的类和方法)。
Enhancer既能够代理普通的class,也能够代理接口。Enhancer创建一个被代理对象的子类并且拦截所有的方法调用(包括从Object中继承的toString和hashCode方法)。Enhancer不能够拦截final方法,例如Object.getClass()方法,这是由于Java final方法语义决定的。基于同样的道理,Enhancer也不能对final类进行代理操作。
事务
Spring将JDBC的事务概念带到了业务层中,同样继承了ACID特性,同样也有四种隔离级别
只不过开启/提交/回滚的操作交给Spring来执行,而不用自行编码
一般只需一个注解@Transactional 修饰方法。那么整个方法的代码块都将以事务的规则执行
事务传播行为
当事务方法被另外一个事务方法调用时,必须指定事务应该如何传播
例如,方法可能继续在当前事务中执行,也可以开启一个新的事务,在自己的事务中执行。
REQUIRED
如果外部方法开启事务并且是 REQUIRED 的话,所有 REQUIRED 修饰的内部方法和外部方法均属于同一事务 ,只要一个方法回滚,整个事务都需要回滚。如果外部方法没有开启事务的话,REQUIRED 修饰的内部方法会开启自己的事务,且开启的事务相互独立,互不干扰。
REQUIRES_NEW
不管外部方法是否开启事务,REQUIRES_NEW 修饰的内部方法都会开启自己的事务,且开启的事务与外部的事务相互独立,互不干扰。
NESTED
如果当前存在事务,就在当前事务内执行;否则,就执行与 REQUIRED 类似的操作。
SUPPORTS
如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
NOT_SUPPORTED
以非事务方式运行,如果当前存在事务,则把当前事务挂起。
MANDATORY
如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
NEVER
以非事务方式运行,如果当前存在事务,则抛出异常。
Spring事务的实现原理是什么?
Spring有两种事务的实现方式,第一是编程式事务,即通过手动编码的方式,创建TransactionTemplate对象进行execute()传入业务代码或者transactionManager对象通过commit()提交业务代码来实现。第二就是声明式事务,即使用注解的形式直接拦截方法,基于AOP。编程式事务的粒度更小,是代码块级别的。而声明式事务的粒度稍大一些是整个方法。
事务操作是AOP的一个核心体现,当一个方法添加@Transactional后,Spring会基于这个类生成代理对象,当使用这个代理对象的方法时,如果有事务,那么会先关闭连接的autocommit,先执行业务逻辑。若无异常,代理逻辑就会提交。若出现异常,就会进行回滚操作。