虚拟内存
局部性原理
在绝大多数程序的运行过程中,当前指令大概率都会引用最近访问过的数据,也就是说,程序的数据访问会表现出明显的倾向性。这种倾向性,我们就称之为局部性原理 (Principle of locality)。
局部性原理主要有两个方面:
- 时间局部性,也就是说被访问过一次的内存位置很可能在不远的将来会被再次访问
- 空间局部性,如果一个内存位置被引用过,那么它邻近的位置在不远的将来也有很大概率会被访问
基于这个原理,我们可以做出一个推论:无论一个进程需要的总资源有多大,在任一时刻,它需要的物理内存都是其中的少部分。所以CPU 只需为每个进程保留很少的物理内存就可以保证进程的正常运行。
虚拟内存
基于局部性原理,我们无需将该进程需要的所有资源都装入内存,而是部分装入,待使用malloc等分配内存的接口时,才会将相应的数据页装入内存。
但是对于程序本身来说,每个程序看见的内存空间都是远大于实际可用空间且互相独立的
比如进程 A 中有个变量 a,它的地址是 0x100,但是进程 B 中也有个变量 b,它的地址也是 0x100。但这并不会造成冲突,因为进程 A 的地址空间与进程 B 的地址空间是独立的,相互不影响。
这就是虚拟内存:现代物理内存的容量增长已经非常快速了,然而还是跟不上应用程序对主存需求的增长速度,对于应用程序来说内存还是可能会不够用,因此便需要一种方法来解决这两者之间的容量差矛盾。为了更高效地管理内存并尽可能消除程序错误,现代计算机系统对物理主存 RAM 进行抽象,实现了虚拟内存 (Virtual Memory, VM)
映射
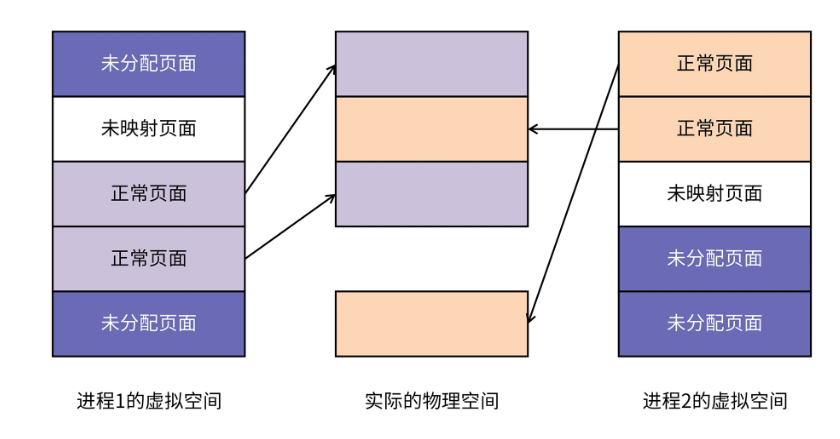
CPU 充分利用程序局部性原理,提出了虚拟内存和物理内存的映射 (Mapping) 机制
这种映射关系是以页为单位的,操作系统管理着这种映射关系,所以用户就不用再操心物理内存的使用情况了,你看到的内存就是虚拟内存。
在虚拟内存中连续的页面,在物理内存中不必是连续的。只要维护好从虚拟内存页到物理内存页的映射关系,你就能正确地使用内存了。不过虚拟地址空间往往与机器字宽有关系。例如 32 位机器上,指向内存的指针是 32 位的,所以它的虚拟地址空间是 2 的 32 次方,也就是 4G。在 64 位机器上,指向内存的指针就是 64 位的,但在 64 位系统里只使用了低 48 位,所以它的虚拟地址空间是 2 的 48 次方,也就是 256T。
页表
大多数情况下CPU 和操作系统会一起完成页面的自动映射,不需要你关心其中的机制。
但是当我们在做系统性能优化的时候,理解内存映射的过程就是十分必要的了。例如一个性能很差的程序就有可能是因为缺页中断过多导致的。
映射的过程,是由 CPU 的内存管理单元 (Memory Management Unit, MMU) 自动完成的,但它依赖操作系统设置的页表。页表的本质是页表项 (Page Table Entry, PTE) 数组,虚拟空间中的每一个页在页表中都有一个 PTE 与之对应,PTE 中会记录这个虚拟内存页所对应的实际物理页的起始地址。
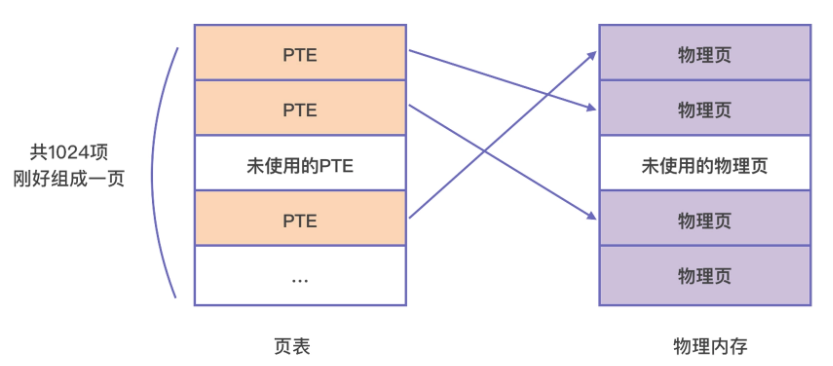
每个页表项大小为4字节,一页的页表项有1024个,其所能支持的空间就是 4M
当然对于拥有更大地址空间的计算机,单级页表结构肯定是不能完整描述内存的,所以需要引入多级页表结构

页中断
页中断和普通的中断一样,它的中断服务程序入口也在中断向量表中,但它是由 MMU 产生的硬件中断。
页中断有两类重要的类型:写保护中断和缺页中断。正是这两类中断在整个系统的后台默默地工作着,就像守护神一样支撑着内存系统正常工作。
大多数时候,我们可以不知道它们的存在。但是有时候,程序设计有缺陷就有可能造成中断频繁发生,从而带来巨大的性能下降。
fork的原理
父进程和子进程不仅可以访问共有的变量,还可以各自修改这个变量,并且这个修改对方都看不见。这其实就是写时复制机制,实现原理便是写保护中断。
fork 的第一个动作是把 PCB 复制一份,进程与子进程的代码段、数据段、堆和栈都是相同的,这是因为它们拥有相同的页表,自然也有相同的虚拟空间布局和对物理内存的映射。如果父进程在 fork 子进程之前创建了一个变量,打开了一个文件,那么父子进程都能看到这个变量和文件。
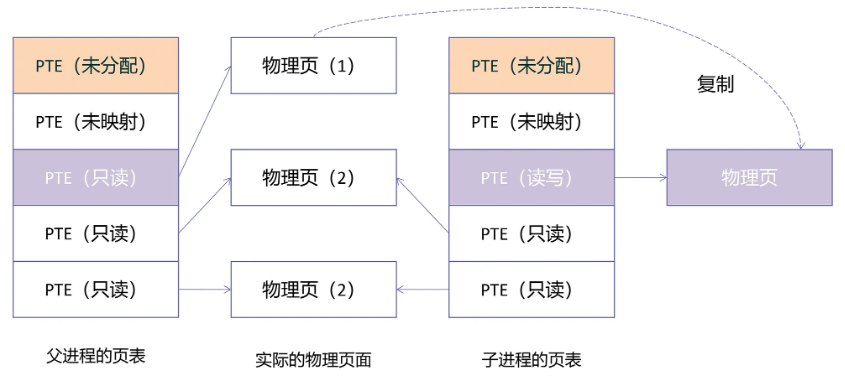
fork 的第二个动作是复制页表和 PCB 中的 VMA ,并把所有当前正常状态的数据段、堆和栈空间的虚拟内存页,设置为不可写,然后把已经映射的物理页面的引用计数加 1。
这一步只需要复制页表和修改 PTE 中的写权限位可以了,并不会真的为子进程的所有内存空间分配物理页面,修改映射,所以它的效率是非常高的。这时,父子进程的页表的情况如下图所示:

这两个动作执行完后,fork 调用就结束了。
此时,由于有父进程和子进程两个 PCB,操作系统就会把两个进程都加入到调度队列中。
当父进程得到执行,它的 IP 寄存器还是指向 fork 调用中,所以它会从这个调用中返回,只不过返回值是子进程的 PID。当子进程得到执行时,它的 IP 寄存器也是停在 fork 调用中,它从这个调用中返回,其返回值是 0。
不管是父进程还是子进程,它们接下来都有可能发生写操作,但在 fork 的第二步操作中,已经将所有原来可写的地方都变成不可写了,所以这时必然会发生写保护中断。
Linux 系统的页中断的入口地址是 do_page_fault,在这个函数里,它会继续判断中断的类型。由于发生中断的虚拟地址在VAM中是可写的,在 PTE 中却是只读的,可以断定这是一次写保护中断。这时候,内核就会转而调用 do_wp_page 来处理这次中断,wp 是 write protection 的缩写。
在 do_wp_page 中,系统会首先判断发生中断的虚拟地址所对应的物理地址的引用计数,如果大于 1,就说明现在存在多个进程共享这一块物理页面,那么它就需要为发生中断的进程再分配一个物理页面,把老的页面内容拷贝进这个新的物理页,最后把发生中断的虚拟地址映射到新的物理页。这就完成了一次写时复制 (Copy On Write, COW)。具体过程如下图所示:
execve原理
execve 的作用是使用当前进程执行一个新的可执行程序,当调用execve时:
- 清空页表,这样整个进程中的页都变成不存在了,一旦访问这些页,就会发生页中断
- 打开待加载执行的文件,在内核中创建代表这个文件的 struct file 结构
- 加载和解析文件头,文件头里描述了这个可执行文件一共有多少 section
- 创建相应的VMA来描述代码段,数据段,并且将文件的各个 section 与这些内存区域建立映射关系
- 处理依赖的其他共享库文件
- 最后跳转到可执行程序的入口处执行
execve 的实现并不负责将文件内容加载到物理页中,它只建立了这种文件 section与内存区域的映射关系
真正负责加载文件内容的是缺页中断:
在 execve的执行步骤中,我们讲了,内核为可执行程序创建一个VMA对象,然后将它的 vm_file 属性设成第 2 步所打开的文件,这就建立起了内存区域和文件的映射关系。这个内核区域的区间首地址、区间尾地址和控制权限,都是由第 3 步解析的信息决定的。例如.text 段被加载到的内存首地址,也就是链接时所决定的起始地址,它就决定了内存代码段的起始地址。
由于第 1 步把页表都清空了,这就导致 CPU 在加载指令时会发现代码段是缺失的,此时就会产生缺页中断。Linux 内核用于处理缺页中断的函数是 do_no_page,如果内核检查,当前出现缺页中断的虚拟地址所在的 VMA(虚拟地址落在该内存区域的 vm_start 和 vm_end 之间)存在文件映射 (vm_file 不为空),那就可以通过虚拟内存地址计算文件中的偏移,这就定位到了内存所缺的页对应到文件的哪一段。
然后内核启动磁盘 IO,将对应的页从磁盘加载进内存,完成页表项的记录,一次缺页中断就这样被解决了。
所以可执行程序的加载不是一次性完成的,而是由缺页中断根据需要,将文件的内容以页为单位加载进内存的,一次只会加载一页。
mmap原理
私有匿名映射:用于分配堆空间
私有匿名映射很简单:在调用 mmap 时,只需要在文件映射区域分配一块内存,然后创建这块内存所对应的VMA就结束了。当访问到这块虚拟内存时,由于这块虚拟内存都没有映射到物理内存上,就会发生缺页中断。
但这一次的缺页中断与 execve时的缺页中断不一样,这次是匿名映射,所以关联文件属性为空。此时,内核就会调用 do_anonymous_page 来分配一个物理内存,并将整个物理页全部初始化为 0,然后在页表里建立起虚拟地址到物理地址的映射关系。
私有文件映射:用于加载动态链接库
则借助文件的 inode 结构共享文件的物理缓存页,当发生写操作时,则会出现写时复制,从而保证每一个进程中都有自己的副本;
共享文件映射,用于多进程之间通讯
在私有文件映射的基础上,只取消了写时复制,这样一个进程就可以看到其他进程对这个页的修改了;
共享匿名映射,用于父子进程之间通讯
借助了虚拟文件系统。内核在父子进程间,使用自己创建的虚拟文件和共享文件映射,来实现共享匿名映射。